村上春树
实锤!村上春树、史蒂芬·金盗版书成训练数据,AI 巨头无一幸免
为了训练大型语言模型,OpenAI、Meta、谷歌、微软等公司未经许可,从互联网上收割了数百万受版权保护的作品,在版权法的灰色地带中游弋。如今,OpenAI目前正面临大量的官司,原告称该公司训练数据集中的大多数书籍来自盗版来源和非授权网站。一旦被判侵权,公司有可能将面临巨额罚款或重构算法的局面。这也导致,如今AI公司越来越不愿意分享AI训练数据的详细信息。站长网2023-08-23 18:08:460000

热点
李彦宏和马化腾,都想通了
2025-02-18 14:54:07新能源汽车开门红:1月销量、渗透率创同期历史新高
2025-02-16 10:48:12马斯克旗下xAI发布Grok3模型 包含mini、Reasoning等版本
2025-02-18 14:10:29春晚才过两周机器人就进化成这了:算法完成升级 能应对任意舞蹈挑战
2025-02-16 10:41:23新势力周销量榜更新:小鹏重回第一、小米排在第三
2025-02-18 14:08:26腾讯回应微信接入DeepSeek:灰度测试 免费使用R1满血模型
2025-02-16 10:38:00接不接DeepSeek?互联网大厂的新天问
2025-02-18 14:03:17百度、OpenAI等大模型免费用 专家:DeepSeek迫使头部玩家打破封闭生态
2025-02-16 10:31:38换个名字获客成本降到不足1美金,“大神”又推火了一个AI App?
2025-02-18 09:52:20Meta 正在大力投资 AI 驱动的类人机器人:希望成为机器人的 Android
2025-02-16 10:22:14
关注
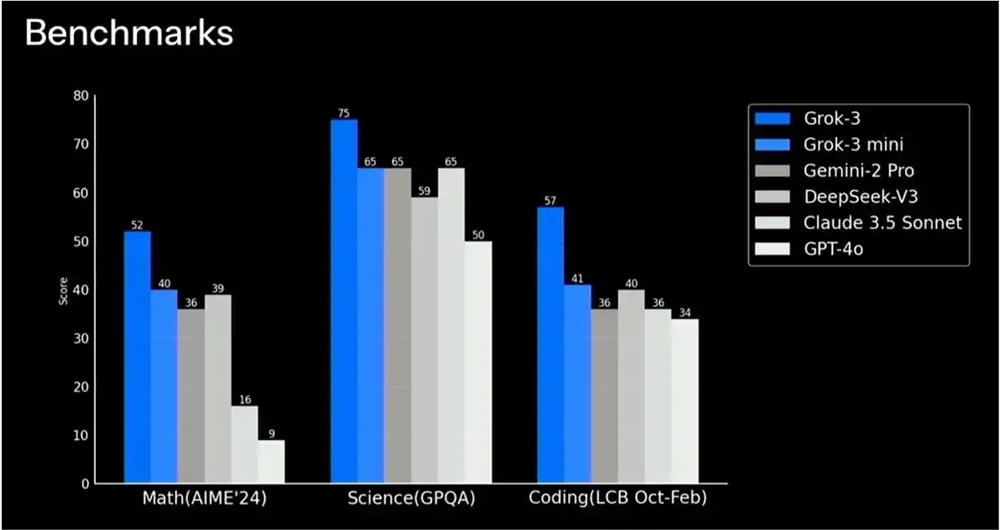
马斯克旗下xAI发布Grok3模型 包含mini、Reasoning等版本
2025-02-18 14:10:29争相拥抱DeepSeek,“学而思们”的野心与忧虑
2025-02-12 18:19:12新势力周销量榜更新:小鹏重回第一、小米排在第三
2025-02-18 14:08:26接入了DeepSeek后的飞书,强大到我有点陌生。
2025-02-12 18:12:58接不接DeepSeek?互联网大厂的新天问
2025-02-18 14:03:17商业导师们全面拥抱DeepSeek
2025-02-12 17:41:51换个名字获客成本降到不足1美金,“大神”又推火了一个AI App?
2025-02-18 09:52:20
千亿美元收购,马斯克是给OpenAI送财还是送灾?
2025-02-12 15:07:25马化腾再次短暂登顶中国富豪榜 腾讯AI、游戏领域表现亮眼
2025-02-18 09:44:50
千万网红鼻祖开播,一小时狂卖5000多单,只赚26元?
2025-02-12 15:05:09