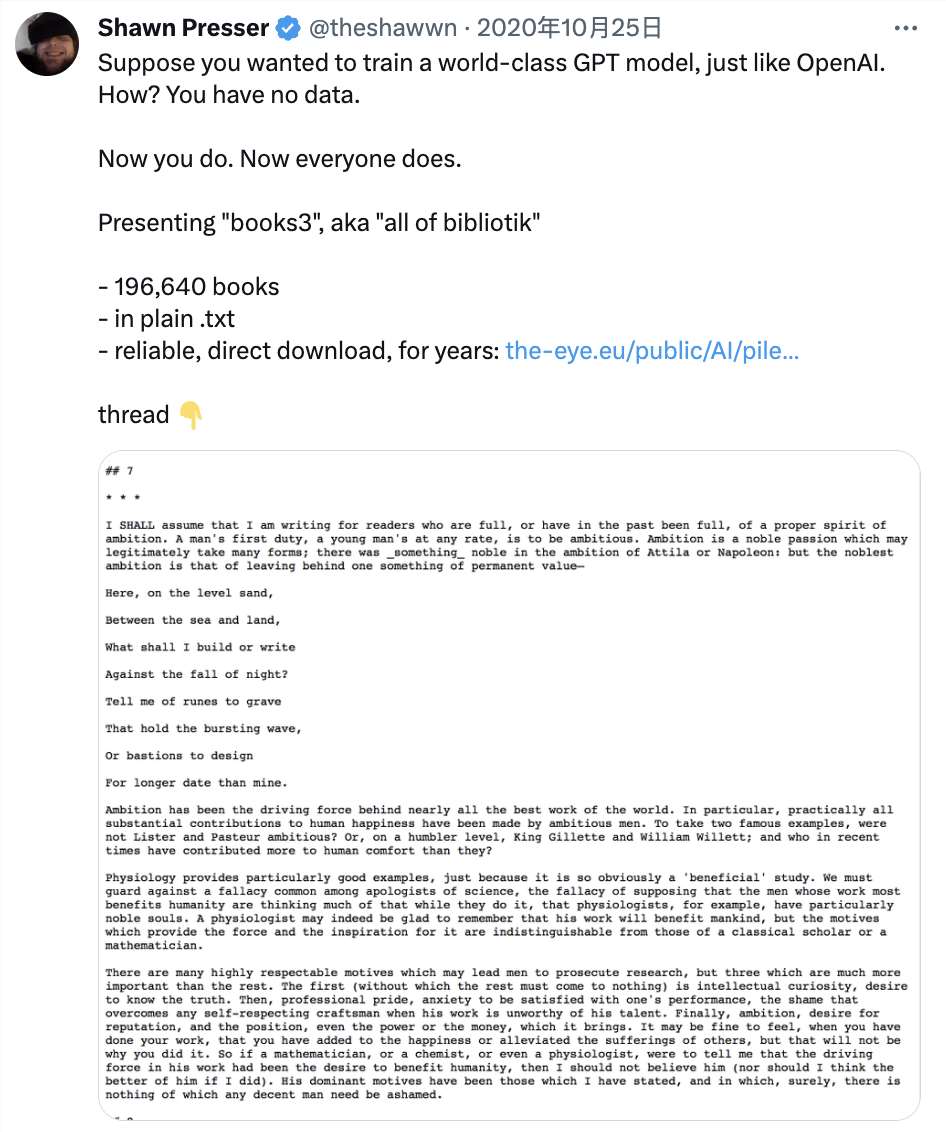
实锤
实锤!村上春树、史蒂芬·金盗版书成训练数据,AI 巨头无一幸免
为了训练大型语言模型,OpenAI、Meta、谷歌、微软等公司未经许可,从互联网上收割了数百万受版权保护的作品,在版权法的灰色地带中游弋。如今,OpenAI目前正面临大量的官司,原告称该公司训练数据集中的大多数书籍来自盗版来源和非授权网站。一旦被判侵权,公司有可能将面临巨额罚款或重构算法的局面。这也导致,如今AI公司越来越不愿意分享AI训练数据的详细信息。站长网2023-08-23 18:08:460000

热点
抖音、小红书“反精致”崛起,为何粗糙真实更得人心?
2025-02-12 10:27:31赢下精品短剧春节档,腾讯视频靠“战略纵深”
2025-02-13 18:00:17接入了DeepSeek后的飞书,强大到我有点陌生。
2025-02-12 18:12:58商业导师们全面拥抱DeepSeek
2025-02-12 17:41:51欢迎来到,短剧的“细糠时代”?
2025-02-12 15:20:18千亿美元收购,马斯克是给OpenAI送财还是送灾?
2025-02-12 15:07:25千万网红鼻祖开播,一小时狂卖5000多单,只赚26元?
2025-02-12 15:05:09DeepSeek算力卡脖子,高校AI研究遇瓶颈?华为联合15校给出最强解法
2025-02-12 13:56:21作业帮“制霸”全球,头部语言产品吸金能力堪比中重度游戏
2025-02-12 09:29:33我的媒介漂流十年——在AI出现以前
2025-02-12 09:15:11
关注
AI产品数据对比:一分没花的DeepSeek一骑绝尘,Kimi六小龙花钱还受伤
2025-02-10 08:41:45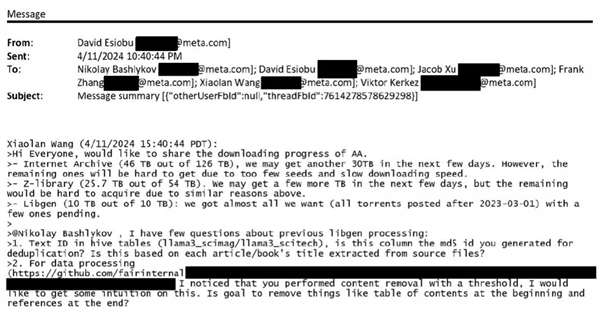
为训练AI不择手段!Meta被曝下载数十TB盗版电子书
2025-02-10 08:38:57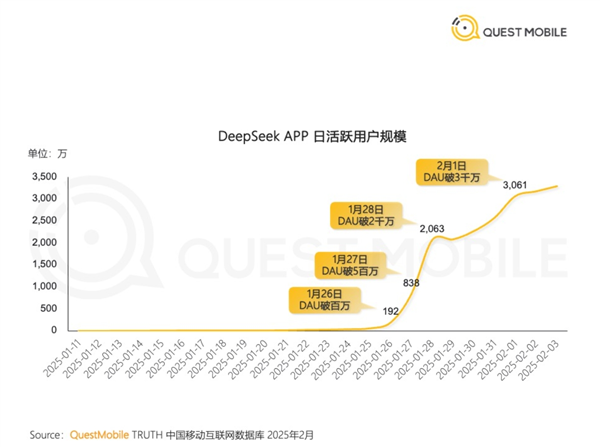
中国AI新秀爆火 DeepSeek成史上最快突破3000万日活App
2025-02-10 08:38:56
雷军驾驶小米YU7参与冬测:表现不错 测试任务圆满完成
2025-02-10 05:11:19
用DeepSeek“赚钱”网课泛滥 专家:普通用户不用花钱学
2025-02-10 05:11:18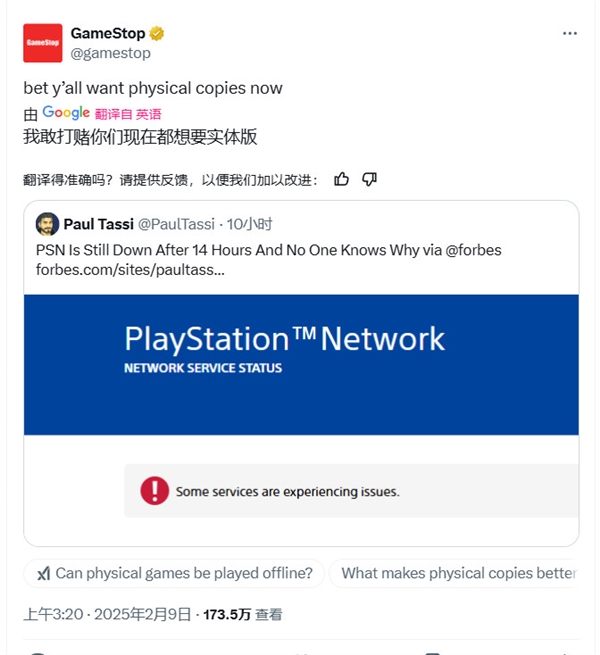
索尼PSN严重宕机!超过24小时才恢复:实体游戏零售商在线补刀
2025-02-10 05:11:17京东外卖“低佣”入局,美团回应“30%高佣”质疑
2025-02-10 05:11:12|美团开放个人摄影师入驻,搅热500亿市场?
2025-02-10 03:41:55《哪吒2》改写中国影史背后,这些配角燃爆了社交媒体
2025-02-10 03:21:53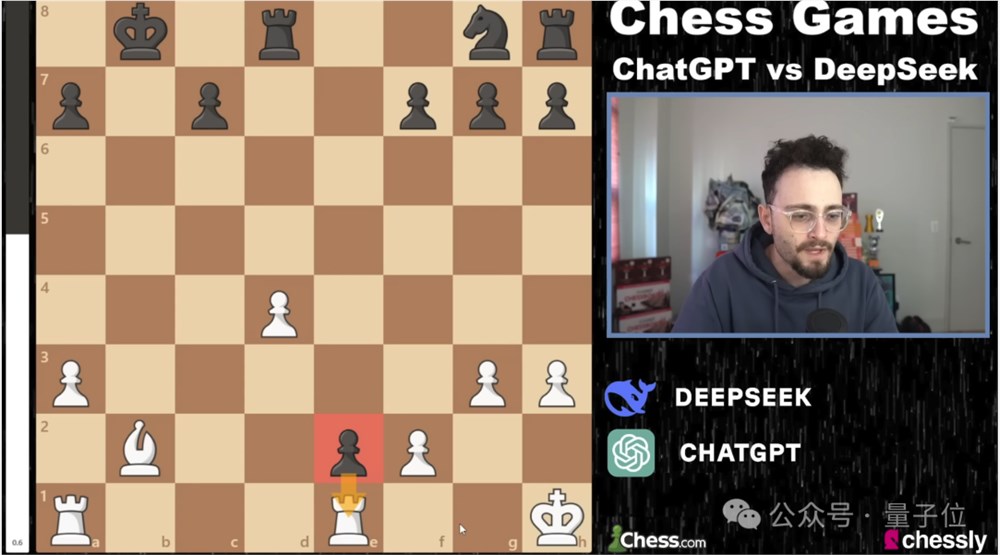
DeepSeek下棋靠忽悠赢了ChatGPT,网友:孙子兵法都用上了
2025-02-10 03:17:44


