CatBERTa:一种基于 Transformer 的AI模型 能够处理人类可理解的文本数据
CatBERTa 是一种基于 Transformer 的人工智能模型,旨在通过文本输入进行能量预测。该模型建立在预训练的 Transformer 编码器之上,这是一种在自然语言处理任务中表现出色的深度学习模型。
CatBERTa 的独特之处在于它能够处理人类可理解的文本数据,并添加用于吸附能量预测的目标特征。这使得研究人员可以以简单易懂的格式提供数据,提高了模型预测的可用性和可解释性。
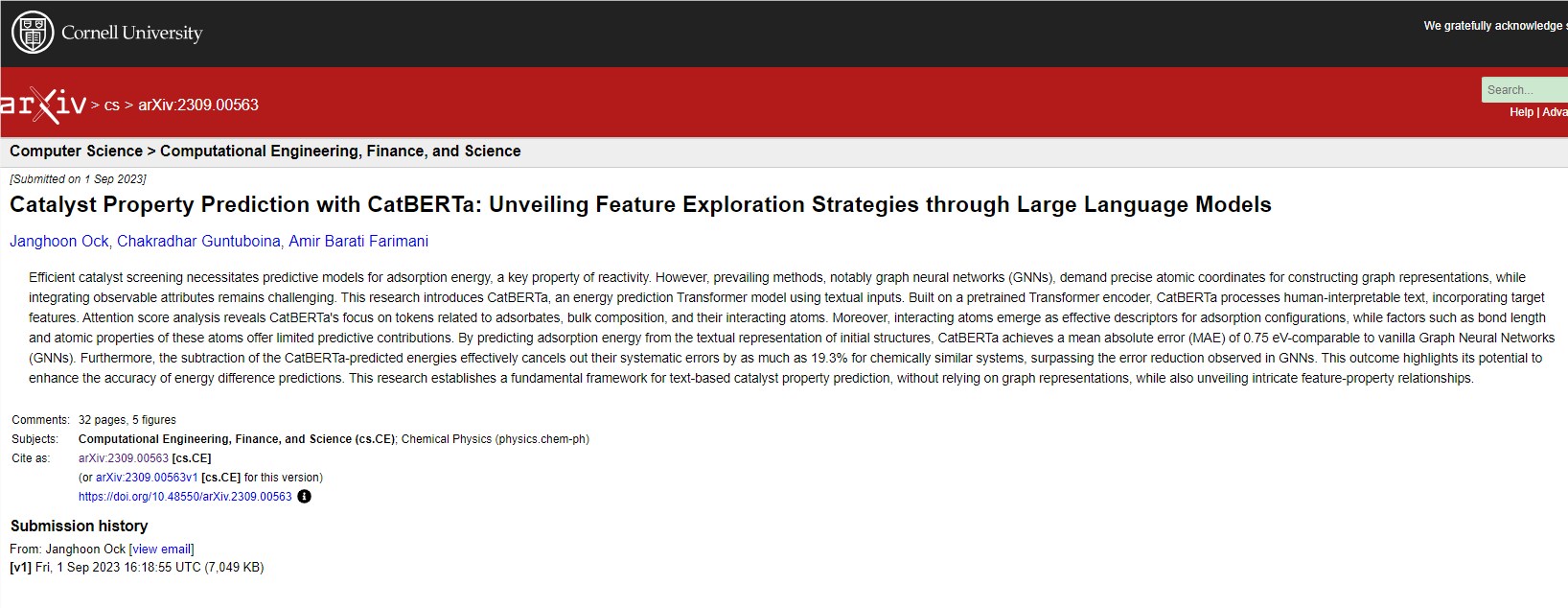
论文地址:https://arxiv.org/abs/2309.00563
研究发现,CatBERTa 倾向于集中关注输入文本中的特定标记。这些指标与吸附物(附着在表面上的物质)、催化剂的整体组成以及这些元素之间的相互作用有关。CatBERTa 似乎能够识别和重视影响吸附能量的催化系统的关键因素。
研究还强调了相互作用原子作为描述吸附排列的有用术语的重要性。吸附剂中的原子与块体材料中的原子相互作用对于催化至关重要。有趣的是,与吸附能量的准确预测几乎没有影响的是链接长度和这些相互作用原子的原子组成。这个结果表明,CatBERTa 可能会优先考虑任务的重要内容,并从文本输入中提取最相关的信息。
在准确性方面,CatBERTa 在吸附能量预测中显示出0.75电子伏特的平均绝对误差(MAE)。这个精度水平与广泛使用的图神经网络(GNNs)相当,用于进行此类预测。CatBERTa 还具有额外的好处,即对于化学上相同的系统,从 CatBERTa 估计的能量可以通过彼此相减有效地消除系统误差,达到19.3%。这表明,CatBERTa 有潜力大大减少催化剂筛选和反应性评估中预测能量差异的错误,这是催化剂研究中至关重要的一部分。
总之,CatBERTa 提供了一种可能的替代传统的 GNNs 的方法。它展示了提高能量差异预测精度的可能性,为更有效和精确的催化剂筛选程序打开了大门。
我在直播间“卖鱼”,一年卖出8个亿
在拥有千年饮食文化的中国,一道菜就能成就一个赛道。这道诞生于重庆的川菜——酸菜鱼,因为口感丰富、做法独特,从上世纪90年代开始风靡全国,成为大小饭店中一道经典名菜。酸菜鱼成为餐桌爆品后,线下也出现了多家主打这道菜的餐饮店,例如太二酸菜鱼、鱼你在一起等品牌。凭借“吃货”对酸菜鱼的喜爱和消费,太二品牌在2018年中国酸菜鱼市场排名第一,为母公司九毛九贡献了超四成营收,助其于2020年1月成功上市。站长网2023-04-23 09:21:510000网易游戏推出家长关爱平台 支持一键禁止游戏充值/登录
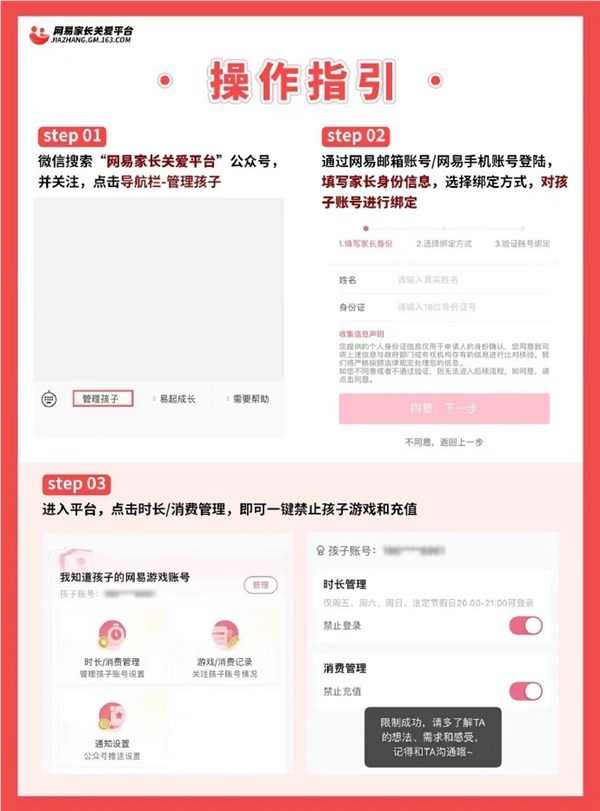
网易游戏近日宣布推出家长关爱平台,新增了一键禁止游戏充值和登录的功能,旨在帮助家长更方便地管理孩子的游戏行为,防止沉迷和过度消费。通过绑定孩子的游戏账号,家长们可以在自己的手机上进行全方位的管理。只需一个按钮,就可以禁止孩子充值和登录游戏。这一功能的推出,使得家长们可以更好地控制孩子的游戏时间和消费,确保孩子能够健康游戏。站长网2023-12-04 11:02:470000抖音:即日起 抖音VR直播在苹果Vision Pro支持下载体验
今日,抖音集团在微信公众号上宣布,其最新推出的抖音VR直播功能现已在AppleVisionPro平台上线,供用户下载体验。这项技术革新带来了全新的观看体验:通过小范围6DoF技术,观众的视线所及之处,内容都能实时追随,无论从哪个角度观看,都能享受到超清的正面视角。3D直播技术让画面突破传统屏幕限制,与现实世界无缝融合,为用户带来前所未有的立体观看体验。站长网2024-07-11 08:54:220000国产AI掀起“百模大战”,突围ChatGPT还要多久?
我们目前没有训练GPT-5,也不会在短期内进行训练。近日,在麻省理工学院举办的“TheFutureofBusinesswithAI”论坛上,OpenAI的首席执行官SamAltman首次回应《暂停AI巨型实验》的公开信。按照这位“ChatGPT之父”的说法,“建更大的模型,喂更多的数据”已经不能奏效,GPT-4的硬件条件也到了天花板。站长网2023-05-08 17:48:150000