反盗版组织下线AI训练数据集 “Books3” Meta大模型也曾使用
本文概要:
1. 反盗版组织成功要求在线盗版书籍资源库 The Eye 下线 AI 训练数据集 "Books3"。
2. "Books3" 数据集包含了37GB 的文本,用于训练人工智能模型,已被多家公司使用。
3. 反盗版组织表示 AI 对版权产生了新的挑战,计划继续打击其他存有该数据集的网站。
近日,反盗版组织成功要求在线盗版书籍资源库 The Eye 下线 AI 训练数据集 "Books3" 的事件。"Books3" 数据集是一个大规模的盗版书籍资源,包含了37GB 的文本,用于训练人工智能模型。
Books3存储库包含196,640本书,全部采用 plain.txt 格式,旨在为新兴的 AI 项目提供与 ChatGPT 制造商 OpenAI 等项目竞争的优势。
丹麦的反盗版组织 Rights Alliance 向 The Eye 发送了 DMCA 通知书,要求其下线该数据集。该组织表示,Books3数据集包含其成员公司出版的约150本书。Rights Alliance 还联系了 AI 模型托管网站 Hugging Face(该网站托管了数据卡和 Books3下载链接)以及 EleutherAI。两个组织都将反盗版组织的目标指向了“The Eye”。
非营利研究组织 EleutherAI 最初发布 Books3作为 AI 训练集 The Pile 的一部分,The Pile 是一个800GB 的开源训练数据块,其中包含22个专门为训练语言模型而设计的其他数据集。
尽管 "Books3" 数据集已被下线,其发布者Shawn Presser(人工智能开发人员和著名开源人工智能支持者) 又在 Twitter 上发布了两个新的下载链接。反盗版组织表示将继续追踪和打击存有该数据集的网站。
尽管如此,大型科技公司在训练 AI 模型时使用版权数据的普遍性,但这些公司并不会公开发布其训练数据,这造成了与个人和非营利项目的不公平竞争。反盗版组织表示,AI 对版权产生了新的挑战,需要加强监管和规范。
据了解,Meta 等公司也使用了 "Books3" 数据集来训练 AI 模型。在描述原始 LlaMA 语言模型的白皮书中,Meta 研究人员将 Books3描述为“用于训练大型语言模型的公开数据集”。Meta 引用了来自The Pile的这个数据集。另外,OpenAI 的 GPT-3模型使用 Books2训练集来训练其 AI。Books1和 Books2都占 GPT-3训练数据的近15%。

蜜雪冰城回应涨价1元尚未全国推广:部分区域试行
近日,网络上流传出上海地区蜜雪冰城饮品涨价的消息,声称每杯饮品价格上调了1元。针对此事,3月18日,蜜雪冰城总部客服人员确认,涨价情况确实存在,但这次调价目前仅限于上海的部分区域,作为一次试行措施。蜜雪冰城总部热线客服进一步解释说,自3月16日起,上海地区的普陀区、静安区、虹口区等七个区域开始试行涨价,根据新的定价方案,饮品价格确实上调了1元。站长网2024-03-19 10:01:460001阿里、百度双双出手,大模型长文本时代终于到来?
AGI时代,越来越近了。全民Long-LLM时代终于到来。本月,中国初创AGI(通用人工智能)公司月之暗面宣布旗下大模型工具KimiChat正式升级到200万字参数量,与五个月前该大模型初次亮相时的20万字相比,提升十倍。KimiChat的升级彻底引爆市场,同时也引起长文本大模型(Long-LLM)细分赛道更加激烈的竞争。(图源:阿里通义千问)站长网2024-03-24 17:23:220000百度萝卜快跑无人出租车上热搜 何小鹏:建议赶紧改端到端
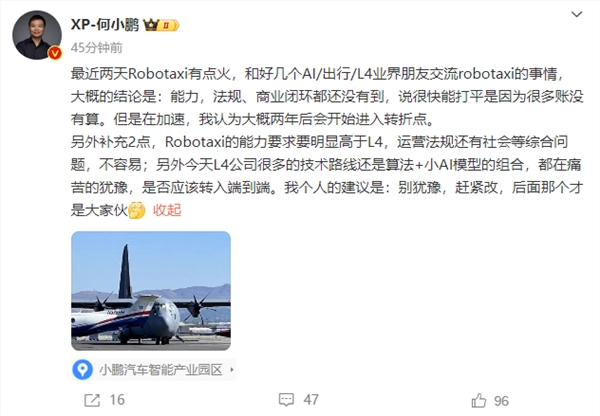
近期,百度在武汉推出的萝卜快跑无人出租车服务受到了广泛关注和热烈追捧,不仅吸引了众多国内乘客,甚至连外国人也纷纷前去体验。这一现象不仅让萝卜快跑成为热门话题,也显著提升了百度的股价。站长网2024-07-11 15:33:180000京东许冉:研发投入累计超1000亿 大模型将应用于多个场景
在2023年世界互联网大会乌镇峰会上,京东集团首席执行官许冉在互联网企业家论坛上发表演讲,阐述了京东以供应链为基础的新型实体企业的发展理念。她强调了数字技术与实体经济深度融合对于创新的重要推动作用,并介绍了京东在技术创新方面的成果和经验。站长网2023-11-09 10:41:250000黑鲨将推出S1 Pro AI智能手表 配备百度“文心一言”技术
黑鲨手机官方宣布,他们将推出一款名为黑鲨智能手表的新型智能设备。据透露,这款智能手表分为黑鲨S1Pro和S1Classic两个版本,它们都搭载了黑鲨首创的游戏健康监测模式。据猜测,黑鲨智能手表能够记录玩家的游戏类型和时长,如果发现游戏时间过长,将会向玩家发出健康提醒。站长网2023-10-16 11:14:320000