Open LLM榜单再次刷新,比Llama 2更强的「鸭嘴兽」来了
为了挑战 OpenAI 的 GPT-3.5和 GPT-4等闭源模型的主导地位, 一系列开源模型力量正在崛起,包括 LLaMa、Falcon 等。最近,Meta AI 发布了 LLaMa-2模型,被誉为开源领域最强的大模型,很多研究者也在此基础上搭建自己的模型。比如,StabilityAI 利用 Orca 风格的数据集对 Llama270B 模型进行了微调,打造出了 StableBeluga2,在 Huggingface 的 Open LLM 排行榜中也取得了不错的成绩。
最近,Open LLM 榜单的排行又发生了新的变化,一个名叫 Platypus(鸭嘴兽)的模型登上了榜首。
概括地说,Platypus 同样是基于 Llama2微调。来自波士顿大学的作者使用了 PEFT 和 LoRA 以及数据集 Open-Platypus 进行优化。

在一篇论文中,作者对 Platypus 进行了详细的介绍:

论文地址:https://arxiv.org/abs/2308.07317
本文的贡献主要有以下几点:
Open-Platypus 是一个小规模的数据集,由公共文本数据集的精选子集组成。该数据集由11个开源数据集组成,重点是提高 LLM 的 STEM 和逻辑知识。它主要由人类设计的问题组成,只有10% 的问题是由 LLM 生成的。Open-Platypus 的主要优势在于其规模和质量,它可以在很短的时间内实现非常高的性能,并且微调的时间和成本都很低。具体来说,在单个 A100GPU 上使用25k 个问题训练13B 模型只需5个小时。
描述了相似性排除过程,减少数据集的大小,并减少数据冗余。
详细分析了始终存在的开放 LLM 训练集与重要 LLM 测试集中包含的数据相污染的现象,并介绍了作者避免这一隐患的训练数据过滤过程。
介绍了对专门的微调 LoRA 模块进行选择和合并的过程。
Open-Platypus 数据集
目前,作者在 Hugging Face 上发布了 Open-Platypus 数据集:

污染问题
本文方法优先考虑防止基准测试问题泄漏到训练集中,以避免仅通过记忆产生结果偏差。作者努力追求准确性的同时,也认识到标记重复问题时需要灵活性,因为问题的提出方式多种多样,而且会受到通用领域知识的影响。为了管理潜在的泄漏,作者精心设计了启发式方法,用于手动过滤 Open-Platypus 中与基准问题余弦嵌入相似度超过80% 的问题。他们将潜在泄漏分为三类:(1) 重复;(2) 灰色区域;(3) 相似但不相同。并且,为谨慎起见,他们将所有组别都排除在训练集之外。
重复
这几乎完全复制了测试题集的内容,可能只是稍稍改动了一下单词或稍作重新排列。根据上表中泄漏问题的数量,这是作者认为真正属于污染的唯一类别。具体例子如下:

灰色区域
以下问题被称为灰色区域,包括并非完全重复、属于常识范畴的问题。虽然作者将这些问题的最终评判权留给了开源社区,但他们认为这些问题往往需要专家知识。需要注意的是,这类问题包括指令完全相同,但答案却同义的问题:

相似但不相同
这些问题的具有较高的相似度,但由于问题之间有着细微的变化,在答案上存在着显著差异。

微调与合并
在完善数据集之后,作者将重点放在两种方法上:低秩近似(LoRA)训练和参数高效微调(PEFT)库。与完全的微调不同,LoRA 保留了预训练的模型权重,并在 transformer 层中整合了秩分解矩阵。这就减少了可训练参数,节省了训练时间和成本。起初,微调主要针对注意力模块,如 v_proj、q_proj、k_proj 和 o_proj。后来,根据 He et al. 的见解,过渡到 gate_proj、down_proj 和 up_proj 模块。除了可训练参数小于总参数的0.1% 时,这些模块均显示出了更好的效果。作者对13B 和70B 模型统一采用了这一方法,结果可训练参数分别为0.27% 和0.2%。唯一的差异在于这些模型的初始学习率。
结果
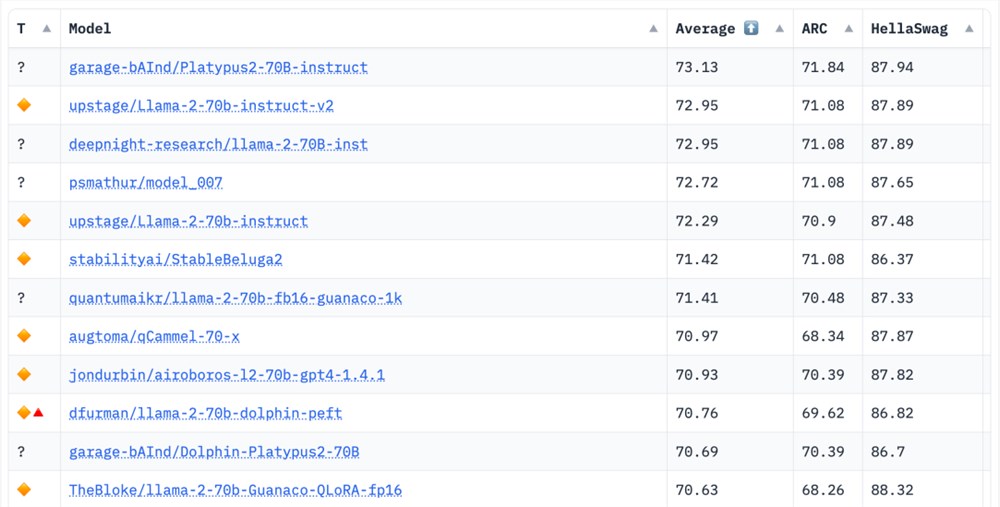
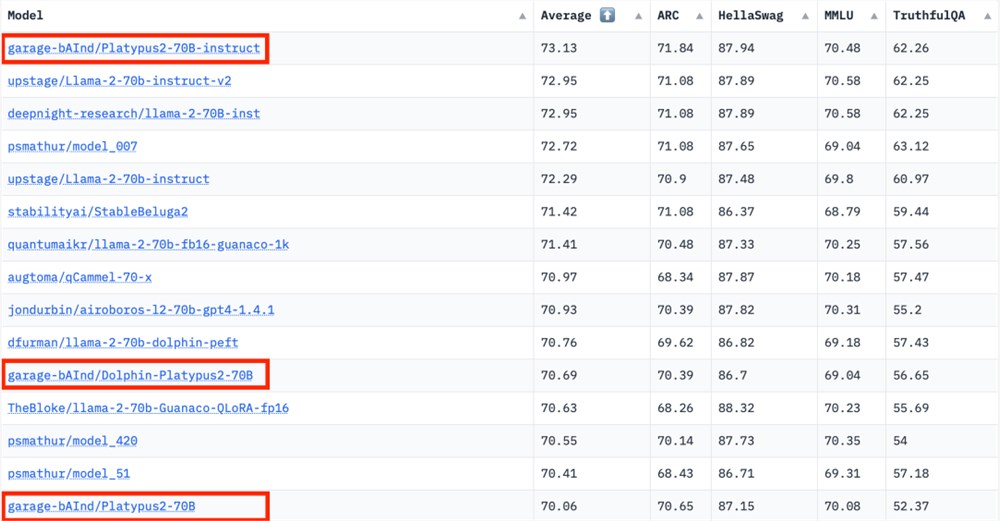
作者将 Platypus 与其他的 SOTA 模型进行了比较。根据2023年8月10日的 Hugging Face Open LLM 排行榜数据,Platypus2-70Binstruct 变体表现优于其他竞争对手,以73.13的平均分稳居榜首:
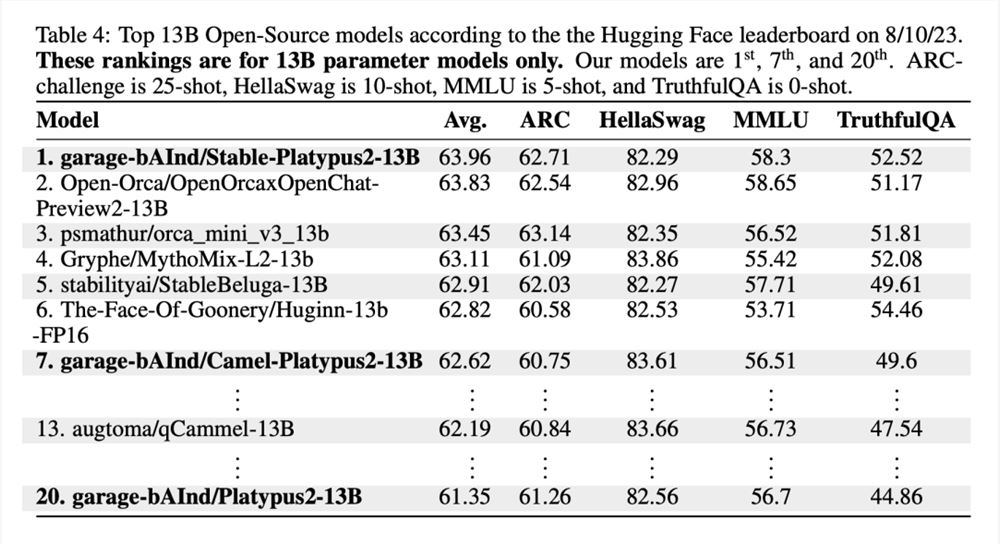
值得注意的是,Stable-Platypus2-13B 模型以63.96的平均分成为130亿参数模型中的佼佼者:
局限性
作为 LLaMa-2的微调扩展,Platypus 保留了基础模型的许多限制条件,并因其有针对性的训练而引入了特定的挑战。它共享 LLaMa-2的静态知识库,而知识库可能会过时。此外,还存在生成不准确或不恰当内容的风险,尤其是在提示不明确的情况下。虽然 Platypus 在 STEM 和英语逻辑方面得到了增强,但它对其他语言的熟练程度并不可靠,而且可能不一致。它偶尔也会产生带有偏见、攻击性或有害的内容。作者表示已经努力减少这些问题,但挑战依然存在,尤其是在非英语语言方面。
Platypus 可能会被滥用于恶意活动,这也是一个令人担忧的问题。开发人员应在部署前对其应用程序进行安全测试。Platypus 在其主要领域之外可能存在局限性,因此用户应谨慎行事,并考虑进行额外的微调以获得最佳性能。用户应确保 Platypus 的训练数据与其他基准测试集之间没有重叠。作者对数据污染问题非常谨慎,避免与在有污点的数据集上训练的模型合并。虽然经过清理的训练数据中确认没有污染,但也不排除有些问题漏掉了。如需全面了解这些限制,请参阅论文中的限制部分。
有人在用小绿书,在小红书偷内容……
分享一个我最近听到的“灰色玩法”……在我停更公众号的一年半,发生了三件大事儿:1、公众号的「小绿书*」上线了2、公众号的「算法推荐放量了」3、公众号可以通过「非群发」,多次推送*小绿书,特指在公众号后台,选择「图文/文字」形式进行发布(类似小红书图文笔记)的内容。这三件事儿的叠加,让一些对流量很敏感的“职业创作者”伺机而动,开始了一件“非常简单、不太光彩、能直接变现”的事情——站长网2024-08-21 14:14:480001Q3净赚170亿: 拼多多一骑绝尘
拼多多无对手?11月28日,继二季度业绩大超预期之后,拼多多(PDD.US)再度交出了一份营收688.4亿元,净利润170.3亿元的惊人财报。其中,拉动增长的板块主要为交易服务板块,该业务同比增幅超300%,营收接近300亿元。拼多多仅仅收取0.6%的佣金,在传统电商消费淡季的三季度,为何交易服务业务收入如此“逆天”?站长网2023-11-29 14:11:000000Faraday Future:某些群体通过传播不实信息破坏公司估值
FaradayFuture今日发文称,最近观察到一系列可疑活动,某些群体正通过传播不实信息、操纵市场情绪来合力破坏公司估值。为了解决上述问题,FaradayFuture将继续通过公开披露提供准确及时的信息,以确保各方平等获得关于公司业绩和前景的事实。站长网2023-09-08 15:22:510000美国加州将监管该地区生成式AI的使用
文章概要:1.加州州长签署行政命令,规范生成式人工智能在政府机构中的使用,引领其他州效仿。2.命令要求风险分析,关注基础设施安全和弱势社区,建立沙箱测试项目,并提供员工培训。3.合作顶尖大学,2024年举办联合峰会,讨论生成式人工智能对州及劳动力的影响。站长网2023-09-08 14:25:070005中国电信30亿元成立AI科技新公司
企查查APP显示,近日,中电信人工智能科技(北京)有限公司成立,注册资本30亿元,经营范围包含:人工智能理论与算法软件开发;人工智能基础软件开发;人工智能应用软件开发;人工智能硬件销售等。该公司由中国电信100%控股。今年11月,中国电信发布了千亿参数大模型星辰语义。星辰语义是中国电信自研的大模型,升级后在幻觉抑制、外推窗口、交互体验和多轮理解四个方面都有显著提升。站长网2023-12-04 10:14:170000














