无需微调,一张照片即可换脸、换背景,NUS等华人团队破局个性化视频生成
这项研究为个性化视频编辑领域带来了新的可能性,使得生成个性化内容变得更加简便和高效。
只要一张参考图片,任何人都可以替换成视频的主角。
随着扩散模型的发展,基于输入文本生成高质量的图片和视频已经成为现实,但是仅使用文本生成视觉内容的可控性有限。
为了克服这个问题,研究人员们开始探索额外的控制信号和对现有内容进行编辑的方法。这两个方向在一定程度上实现了生成过程的可控性,但仍然需要依赖文本来描述目标生成内容。
在实际应用中,我们面临着一个新的需求:如果用户想要生成的内容无法用语言描述呢?
例如,用户想生成某一个普通人的视频,但仅在输入文本中使用普通人的名字是无意义的,因为语言模型无法识别不在训练语料中的个体姓名。
针对这个问题,一种可行的解决方案是基于给定个体训练个性化的模型。
例如,DreamBooth和Dreamix通过多张图片理解个体概念,从而进行个性化的内容生成,不过这两种方法需要对每个个体分别进行学习,并且需要该个体的多张训练图片和精细化调参。
最近,来自新加坡国立大学(NUS)和华为诺亚实验室的研究者们在个性化视频编辑上取得了新的进展,通过多个集成模型的协同工作,无需对个性化概念进行额外的训练和微调,仅仅需要一张目标参考图片,就能实现对已有视频的主角替换、背景替换以及特定主角的文生视频。

项目主页:https://make-a-protagonist.github.io/
论文地址:https://arxiv.org/pdf/2305.08850.pdf
代码地址:https://github.com/Make-A-Protagonist/Make-A-Protagonist
这项研究为个性化视频编辑领域带来了新的可能性,使得生成个性化内容变得更加简便和高效。



介绍
Make-A-Protagonist将视频分为主角和背景,对二者使用视觉或语言参考信息,从而实现主角编辑、背景编辑和特定主角的文生视频。

主角编辑功能允许用户使用相同的场景描述,但通过参考图像来替换视频中的主角。这意味着用户可以使用自己选择的图像来替换视频中的主要角色。

背景编辑功能允许用户使用与原始视频相同的主角描述(例「Suzuki Jimny」),并使用原始视频帧作为视觉信息,但可以更改对场景的文字描述(例如「in the rain」)。这样,用户可以保持相同的主角,但改变场景的描述,营造出不同的视觉效果。

特定主角的文生视频功能将主角编辑和背景编辑结合起来。用户可以使用参考图像作为主角,并对场景进行描述,从而创造出全新的视频内容。此外,对于多主角视频,Make-A-Protagonist还可以对单个或多个角色进行更改。

与DreamBooth和Dreamix不同,Make-A-Protagonist仅需要单张参考图像,不需要对每个概念进行微调,因此在应用场景上更加灵活多样。Make-A-Protagonist为用户提供了一种简便而高效的方式来实现个性化的视频编辑和生成。
方法

Make-A-Protagonist使用多个强大的专家模型,对原视频、视觉和语言信息进行解析,并结合基于视觉语言的视频生成模型和基于掩码的去噪采样算法,实现通用视频编辑。该模型主要由三个关键部分组成:原视频解析,视觉和语言信息解析,以及视频生成。
具体来说,Make-A-Protagonist推理过程包括以下三步:首先使用BLIP-2, GroundingDINO、Segment Anything 和 XMem等模型对原视频进行解析,获得视频的主角掩码,并解析原视频的控制信号。
接下来,使用CLIP和DALL-E2Prior对视觉和语言信息进行解析。最后,使用基于视觉语言的视频生成模型和基于掩码的去噪采样算法,利用解析信息生成新的内容。
Make-A-Protagonist的创新之处在于引入了基于视觉语言的视频生成模型和基于掩码的去噪采样算法,通过整合多个专家模型并解析、融合多种信息,实现了视频编辑的突破。
这些模型的运用使得该系统更加精准地理解原视频、视觉和语言信息,并能够生成高质量的视频内容。
Make-A-Protagonist为用户提供了一款强大而灵活的工具,让他们能够轻松进行通用的视频编辑,创作出独特而令人惊艳的视觉作品。
1.原视频解析
原视频解析的目标是获取原视频的语言描述(caption)、主角文字描述、主角分割结果以及ControlNet所需的控制信号。
针对caption和主角文字描述,Make-A-Protagonist采用了BLIP-2模型。
通过对BLIP-2的图像网络进行修改,实现了对视频的解析,并使用captioning模式生成视频的描述,这些描述在训练和视频编辑中用于视频生成网络。
对于主角文字描述,Make-A-Protagonist使用VQA模式,提出问题:「视频的主角是什么?」并使用答案进一步解析原视频中的主角信息。
在原视频中的主角分割方面,Make-A-Protagonist利用上述得到的主角文字描述,在第一帧中使用GroundingDINO模型来定位相应的检测内容,并使用Segment Anything模型获得第一帧的分割掩码。然后,借助跟踪网络(XMem),Make-A-Protagonist得到整个视频序列的分割结果。
除此之外,Make-A-Protagonist利用ControlNet来保留原视频的细节和动作,因此需要提取原视频的控制信号。文中使用了深度信号和姿态信号。
通过这些创新的解析方法和技术,Make-A-Protagonist能够准确地解析原视频的语言描述、主角信息和分割结果,并提取控制信号,为后续的视频生成和编辑打下了坚实的基础。
2.视觉和语言信息解析
对于视觉信号,Make-A-Protagonist在本文中采用CLIP image embedding作为生成条件,为了去除参考图像背景的影响,类似于原视频解析,Make-A-Protagonist使用GroundingDINO和Segment Anything得到参考图像主角的分割掩码,使用掩码将分割后的图像输入CLIP视觉模型,以获取参考视觉信息。
语言信息主要用于控制背景,本文将语言信息用于两方面,一方面使用CLIP语言模型提取特征,作为注意力网络的key和value。
另一方面,使用DALL-E2Prior网络,将语言特征转化为视觉特征,从而增强表征能力。
3.视频生成

3.1视频生成网络训练
为了充分利用视觉信息,Make-A-Protagonist使用Stable UnCLIP作为预训练模型,并对原视频进行微调,从而实现利用视觉信息进行视频生成。
在每个训练迭代中,Make-A-Protagonist提取视频中随机一帧的CLIP image embedding,将其作为视觉信息输入到Residual block中。
3.2基于掩码的去噪采样

为融合视觉信息和语言信息,本文提出基于掩码的去噪采样,在特征空间和隐空间对两种信息进行融合。
具体来说,在特征域,Make-A-Protagonist使用原视频的主角掩码,将主角对应部分使用视觉信息,背景对应部分使用DALL-E2Prior转化后的语言信息:
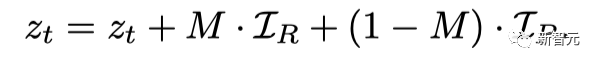
在隐空间中,Make-A-Protagonist将仅使用视觉信息的推理结果和经过特征融合的推理结果按照原视频的主角掩码进行融合:
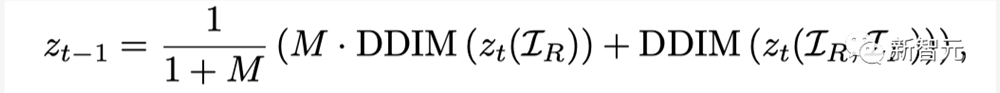
通过特征空间和隐空间的信息融合,生成的结果更加真实,并且与视觉语言表述更加一致。
总结
Make-A-Protagonist引领了一种全新的视频编辑框架,充分利用了视觉和语言信息。
该框架为实现对视觉和语言的独立编辑提供了解决方案,通过多个专家网络对原视频、视觉和语言信息进行解析,并采用视频生成网络和基于掩码的采样策略将这些信息融合在一起。
Make-A-Protagonist展现了出色的视频编辑能力,可广泛应用于主角编辑、背景编辑和特定主角的文生视频任务。
Make-A-Protagonist的出现为视频编辑领域带来了新的可能性。它为用户创造了一个灵活且创新的工具,让他们能够以前所未有的方式编辑和塑造视频内容。
无论是专业编辑人员还是创意爱好者,都能够通过Make-A-Protagonist打造出独特而精彩的视觉作品。
参考资料:
https://make-a-protagonist.github.io/
商汤科技提出Story-to-Motion:从长文本生成人体运动轨迹
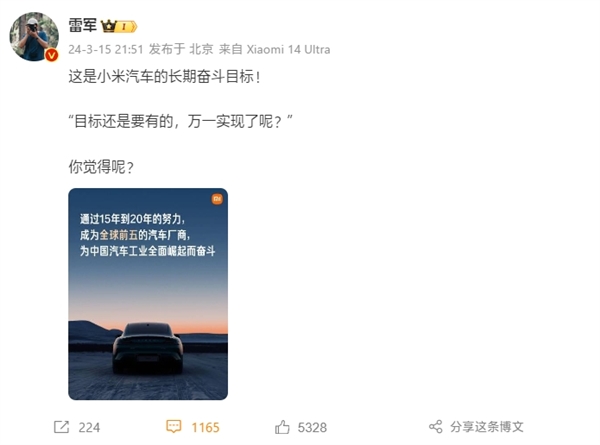
要点:人工智能在动画、游戏和电影领域的应用中,从长篇文本中生成自然人类运动是一个复杂而困难的任务。研究团队提出了一种新的方法,通过三个主要组件,即文本驱动的运动调度、文本驱动的运动检索系统和渐进式掩蔽变换器,成功解决了这一挑战。站长网2023-11-22 11:14:310000雷军:小米汽车目标是全球前五 为中国汽车崛起而奋斗
快科技3月16日消息,小米汽车正式发布会已经定档3月28日,发布会结束之后将公布价格,并且上市即交付,速度非常迅速。雷军最新发文强调了小米汽车的长期奋斗目标:通过15-20年的努力,成为全球前五的汽车厂商,为中国汽车工业全面崛起而奋斗。他表示:目标还是要有的,万一实现了呢?”在此前小米SU7的首场发布会上,雷军还直言小米汽车要媲美保时捷和特斯拉。站长网2024-03-16 11:18:350000Stable Diffusion母公司CEO称:AI是一个1万亿美元的投资机会
据CNBC报道,开源人工智能公司StabilityAI的首席执行官表示,人工智能将是有史以来最大的泡沫。上周,StabilityAI的首席执行官EmadMostaque在与UBS分析师的电话会议上说,关于人工智能:“我认为这将是有史以来最大的泡沫。”他补充说,它仍处于非常早期的阶段,还没有准备好在银行等行业进行大规模的应用。“我称之为‘点AI’机遇,它甚至还没有开始,”他说。站长网2023-07-18 00:04:340000美国点评网站Yelp将加强AI功能 部分功能已在iOS版上线
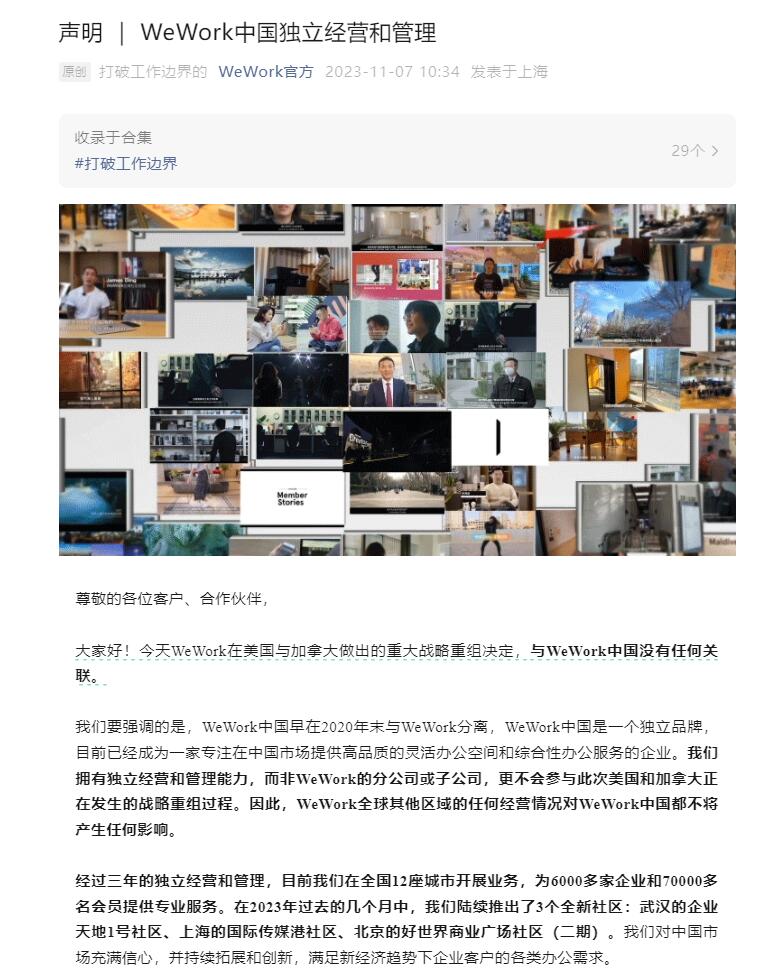
美国点评网站Yelp推出AI摘要、预算工具等新功能,以帮助商家Yelp是领先的商家评论平台,它刚刚推出了冬季产品更新,增加了20多个新功能,提升了其人工智能能力。这些功能帮助商家吸引更多的客户,优化他们的支出,建立在Yelp之前以用户和商家需求为重点的人工智能创新之上。图源备注:图片由AI生成,图片授权服务商Midjourney站长网2024-01-31 09:33:230000WeWork中国:WeWork中国是独立品牌 与WeWork申请破产无关
据国外媒体报道,美国“联合办公空间”公司WeWork计划最早在下周申请破产。WeWork创办于2010年,一度被誉为“未来办公空间的代表”。消息发布后,“共享办公”这种商业模式受到广泛关注和讨论,WeWork股票价格在当天盘后交易中下跌32%。然而,WeWork中国似乎未受影响。在2020年全面实现本土化运营后,WeWork对中国市场积极布局,今年分别在武汉、上海、北京陆续开幕新社区。站长网2023-11-07 14:50:400000