微软发布Phi-4,最强小模型!参数极小、超GPT-4o
微软研究院发布了最强小参数模型——Phi-4。
Phi系列模型自今已经发布了5代,Phi-4也延续了之前的小参数模式只有140亿。
但在GPQA研究生水平、MATH数学基准中,分别达到了56.1和80.4超过了GPT-4o,同时也超过了同类型的开源模型Qwen2.5-14B和Llama-3.3-70B。
而在美国数学竞赛AMC的测试中,Phi-4达到了惊人的91.8分,再次超过了GeminiPro1.5、GPT-4o、Claude3.5Sonnet、Qwen2.5等知名开闭源模型,甚至整体性能可以与4050亿参数的Llama-3.1相媲美。
这也就是说,只要使用了高质量数据和创新训练方法,小参数模型同样可以战胜大参数,但在部署、应用和推理方面极大减少了对AI算力和环境的要求。
使用高质量合成数据
Phi-4能以如此小的参数获得巨大性能,使用高质量合成训练数据是关键环节之一。
传统的大模型通常依赖于从网络抓取或公开数据库获取的真实世界文本作为训练数据,这种方法虽然能够提供丰富的信息来源,但也容易受到噪声干扰和偏见影响。
Phi-4则使用了种子策划、多Agent提示、自我修订工作流、重写和增强以及指令反转等多种合成方法,有效解决了传统无监督数据集的缺点。
种子策划是合成数据生成的起点。Phi-4从多个领域提取高质量的数据种子,为合成数据生成打下坚实基础,使得能够创建针对模型训练目标的练习、讨论和推理任务。
策划的种子包括从网页、书籍和代码库中提取的文段和代码片段,这些内容展示了高复杂性、深度推理和教育价值。为了确保质量,采用了两阶段过滤过程:首先是识别具有强教育潜力的页面,然后是将选定的页面分割成段落,对每个段落进行事实和推理内容的评分。
此外,多Agent提示允许不同智能体之间进行交互对话,从而创造出更加多样化且贴近真实应用场景的交流场景;而自我修订工作流则鼓励模型参与到自身的编辑过程中,以此提高输出内容的质量和一致性。
通过改变任务描述的方式,指令反转可以增加模型处理不同类型问题的能力,进一步增强了其灵活性和适应性。
总体上,一共生成了50种不同类型的合成数据集,涵盖广泛的主题和技能,总计约400B未加权的高质量token数据。
创新训练方法
为了确保phi-4能在广泛的任务类型上表现出色,研究人员使用了一系列针对性创新训练方法,并根据实际需求调整各类数据的比例。尤其是针对长上下文理解能力的需求,phi-4增加了rope位置编码的基础频率至25万次,并相应地降低了最大学习率,以更好地适应更长的文本序列。
这种做法有效提升了模型对于复杂结构化信息的理解力,使其在面对需要综合分析多个段落甚至整篇文章的问题时也能游刃有余。phi-4还特别注重了不同类型数据之间的平衡,避免某类数据过多导致其他方面性能下降的情况发生。
而在 phi-4的后训练过程中,研究团队采用了两种形式的 DPO 数据对模型进行了强化训练。第一种是基于人工标注的 SFT数据,即由专家精心挑选并标记好的问答对;
第二种则是自动构建的 DPO 对,这种方法通过搜索重要的转折点,将原始对话片段拆分成多个选项,并让模型从中选择最优解。通过结合这两种方式,phi-4不仅学会了如何产生更符合预期的回答,还能够在不同情境下灵活调整语气和风格,从而提供更加个性化的交互体验。
此外,phi-4还引入了一些创新性的后训练方法,以增强其在特定领域内的表现。例如,在 STEM领域问题解答方面,phi-4利用了一个名为Math-Shepherd 的工具来进行验证和强化学习。Math-Shepherd 可以自动检查模型生成的答案是否正确,并且在必要时提供额外指导,帮助模型逐步掌握正确的解题思路。
这种方法有效地解决了传统无监督数据集中常见的逻辑不严密等问题,使得 phi-4在数学竞赛类题目上的准确率达到了惊人的80.4%,远超其他同类产品。
此外,针对编程代码评估任务,Phi-4也采取了类似的方法,通过对大量开源项目中的代码片段进行分析和总结,提升了其在该领域的执行效率和准确性。
值得一提的是,微软AI副总裁、phi系列模型的灵魂人物之一Sébastien Bubeck已经离开了微软加入了OpenAI。
李想发全员信自我批评:理想汽车不再单纯追求销量
理想汽车CEO李想近日发布全员信,深入剖析了公司近期面临的挑战,并针对理想MEGA汽车的上市节奏以及过分关注销量的欲望问题,提出了解决方案。站长网2024-03-22 02:32:000000尴尬了!第三方机构报告称仅有24%的用户用Windows 11
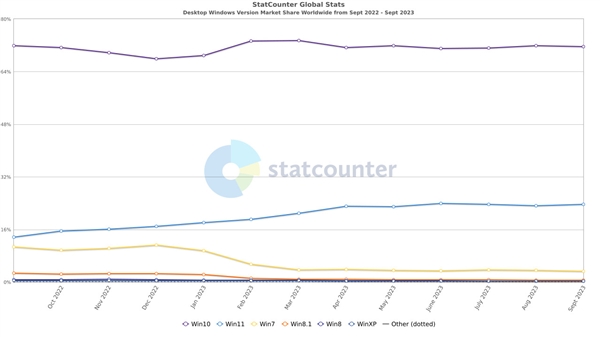
快科技10月2日消息,StatCounter第三方分析机构,揭露了Windows11的最新统计数据。根据调查显示,Windows11的份额依然位居第二,也就是大约23.64%的PC用户在使用。该机构声称,尽管增长了0.57个百分点,但Windows11的市场份额连续第六个月保持相对不变。站长网2023-10-03 09:17:590000联发科技发布天玑 6100+ 5G 芯片:支持高帧率和 AI 相机技术
无厂半导体公司联发科技(MediaTek)于周二推出了其最新的天玑61005G芯片,该芯片属于其新的天玑6000系列。联发科技表示,天玑6100芯片专注于提供功耗效率、鲜艳的显示效果、高帧率、基于人工智能的相机技术、低功耗和次6GHz的5G连接性。据该芯片制造商透露,首批搭载天玑6100芯片的智能手机将在2023年第三季度上市。站长网2023-07-12 09:09:560006OpenAI参投,法律科技公司Harvey获5.7亿元融资
划重点:1.🌐Harvey宣布获得8000万美元B轮融资,估值达7.15亿美元,由凯鹏华盈、红杉资本、OpenAI初创基金等投资。2.⚖️基于OpenAI的GPT-4系列模型,Harvey为律师提供深度定制ChatGPT助手,在法律领域取得优异成绩,全球大律所普华永道成为核心战略合作伙伴。0000京东发布12大AI品类 推动超300万用户换新AI设备
站长之家(ChinaZ.com)5月30日消息:京东在618开门红前夕,正式发布了12大AI品类,旨在推动AI技术的普及与应用,让更多用户享受到前沿科技带来的高效与便捷。站长网2024-05-30 19:46:230000