比对口型还牛!InstructAvatar:实现文字生成指定面部的表情和动作
划重点:
🔍 最新的对话形象生成模型在实现与音频的逼真准确的唇同步方面取得了进展,但在控制和传达形象的细节表情和情感方面仍有不足。
🔍 InstructAvatar 提供了对情感和面部动作进行细粒度控制的文本引导方法,为生成具有情感表达的2D 虚拟形象提供了改进的互动性和泛化能力。
🔍 实验结果表明,InstructAvatar 在细粒度情感控制、口型同步质量和自然性方面优于现有方法,能指定面部的表情和动作。
站长之家(ChinaZ.com) 5月28日 消息:最近,对话形象生成模型在实现与音频的逼真准确口型同步方面取得了进展,但在控制和传达形象的细节表情和情感方面仍有不足,使生成的视频缺乏生动性和可控性。
因此,北京大学的研究团队提出了一种名为 InstructAvatar 的新颖方法,通过自然语言界面来控制虚拟形象的情感和面部动作,从而提供了对生成的视频进行细粒度控制的能力。InstructAvatar可实现的效果包括:
通过自然语言输入控制头像的情绪和面部动作。
利用一个自动注释管道构建训练数据集,使得头像可以根据文本指令和音频进行生成。
生成的头像能够准确同步口型,表情自然且生动。
相比于现有方法,在细粒度情绪控制、口型同步质量和自然度方面有更好的表现。
InstructAvatar 的框架包括两个组件:变分自动编码器(VAE)和基于扩散模型的动作生成器。VAE 用于将动作信息从视频中解耦,并根据音频和指令生成器生成的动作潜变量来生成最终的视频。在推理过程中,通过迭代去噪高斯噪声来获取预测的动作潜变量,并结合用户提供的肖像,使用 VAE 的解码器生成最终的视频。
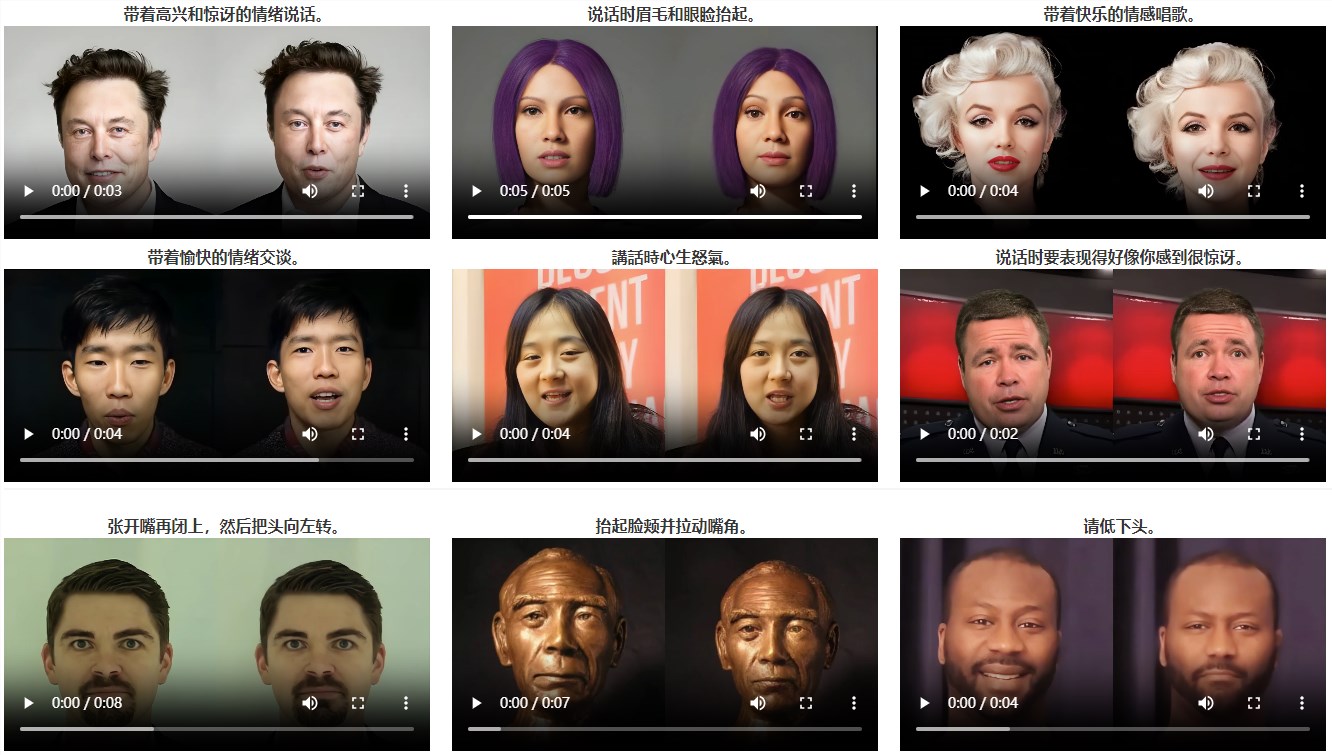
通过与基线模型的定性比较,可以看出 InstructAvatar 在唇同步质量和情感可控性方面取得了良好的效果。此外,模型生成的结果具有增强的自然性,并有效地保留了身份特征。
值得一提的是,该模型仅基于文本输入推断说话的情感,这在直观上提出了一个更具挑战性的任务。模型支持更广泛的指令范围,超出了大多数基线模型的范围。
此外,该模型展现了精确的情感控制能力,并生成了自然的结果。InstructAvatar 具有细粒度的控制能力,并在领域之外的场景中表现出良好的泛化能力。
项目入口:https://top.aibase.com/tool/instructavatar
人工智能利用简陋的X光胸透快速准确诊断心脏功能
据国外媒体报道,研究人员利用深度学习的人工智能模型,成功将简陋的胸部X光片转变为更强大的心脏诊断工具。他们表示,这种新方法可以快速、准确地评估心脏功能和检查疾病。胸部X光是最常用的放射学检查之一,也是医生们常用的诊断肺部和心脏疾病的方法。然而,由于X光是静态图像,无法提供关于心脏运作的详细信息,因此需要进行超声心动图检查。站长网2023-07-13 08:59:530000独家:曾经APP Store下载第一的逗拍关停
逗拍计划于今年6月30日停止运营。这个曾经流出一天的公告,很快就被删去,运营团队似乎仍有些不舍。不过,眼尖的业界仍然留意到了,由此引发讨论纷纷。要知道,这款APP曾数次冲上苹果appstore中国榜下载排行第一。当2013年推出之时,一度和美拍、秒拍、微视等产品争雄——这些产品都曾于斯时一领短视频浪潮数载。如今,短视频的高峰被抖音所统治,其下是追赶的视频号和快手。站长网2023-05-24 11:38:390000中消协出手:反对扫码强制关注公众号 全国范围可举报
快科技6月20日消息,近年来,随着移动支付和二维码的普及,很多餐厅等场所都采用扫码点单。需要注意的是,绝大多数商家都会设置成强制关注公众号才能点单的模式,不关注无法操作。其实《消费者权益保护法》第九条第二款早就有明确规定:消费者有权自主选择提供商品或者服务的经营者,自主选择商品品种或者服务方式,自主决定购买或者不购买任何一种商品、接受或者不接受任何一项服务。”站长网2023-06-21 15:13:140000微软Xbox拥抱AI 走量内卷加剧
游戏AI内卷又迎来新的大玩家,微软发布公告称与InworldAI公司建立合作关系,将生成式AI模型的强大功能带入游戏开发。近两年,游戏行业AIGC进击的消息蔚然成风。无论是公开财报还是演讲发声,AI与行业、公司、产品结合成为无法回避的环节,市场、企业、资本包括股民都聚焦于此。站长网2023-11-09 15:54:380001从社会摇到科目三,梗红人难红
胯部左右摇晃,双手接力摇摆,搭配着“汝为山河过客,却总长叹伤离别”的古风BGM,这就是时下最为出圈的舞蹈,“科目三”。这个如今已经难以考据其起源的网络老梗,最近突然焕发了新生。线下,人们追捧着跳“科目三”的小哥挤爆了海底捞门店和中国黄金;线上,只要愿意一蹭的网红,都能因此得到流量的馈赠。0000