NaturalSpeech 3:可克隆音色和感情的语音合成系统
**划重点:**
1. 🌐 创新性的语音合成系统,NaturalSpeech3,采用分解编解码器和扩散模型,在零样本情况下生成自然语音。
2. 🚀 使用神经编解码器进行语音波形分解,包括内容、韵律、音色和声学细节,以实现细致入微的语音建模。
3. 📈 在LibriSpeech和Ravdess基准测试上,NaturalSpeech3在质量、相似度、韵律和可懂度方面均优于现有TTS系统。
随着大规模文本到语音(TTS)模型的发展,取得了显著进展,但在语音质量、相似度和韵律方面仍存在不足。考虑到语音涉及到多个属性(例如内容、韵律、音色和声学细节),这为生成带来了巨大挑战。
为了解决这一问题,NaturalSpeech3提出了一种创新的TTS系统,采用了新颖的分解扩散模型,以零样本的方式生成自然语音。也就是提供文本和参考音频,可以克隆音色和感情,值得注意的是,NaturalSpeech3目前只有论文。
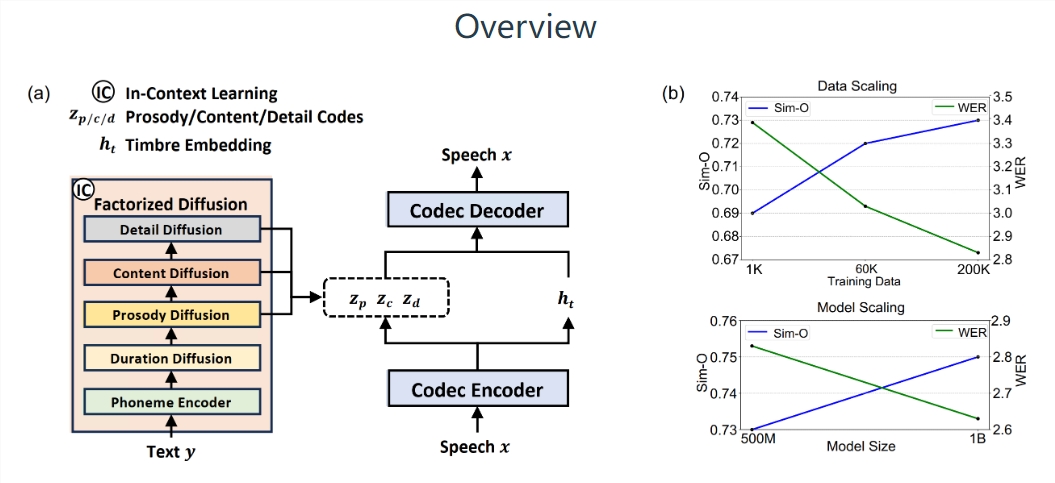
语音建模的关键创新点之一是使用神经编解码器,包含分解的向量量化(FVQ),将语音波形分解成内容、韵律、音色和声学细节等子空间。** 这种分解设计使得NaturalSpeech3能够以分治的方式高效地建模复杂的语音。此外,他们还提出了分解的扩散模型,用于根据相应提示生成每个子空间中的属性。实验证明,NaturalSpeech3在质量、相似度、韵律和可懂度等方面优于现有TTS系统。
在LibriSpeech基准测试中,NaturalSpeech3的性能明显超越了其他系统。对比结果显示,NaturalSpeech3在相似度(Sim-O)、错误率(WER)、音质(CMOS)、语音质量(SMOS)等方面均取得了显著的优势。此外,通过扩大模型规模和训练数据,NaturalSpeech3在200K小时的训练数据和10亿参数的规模下取得了更好的性能。
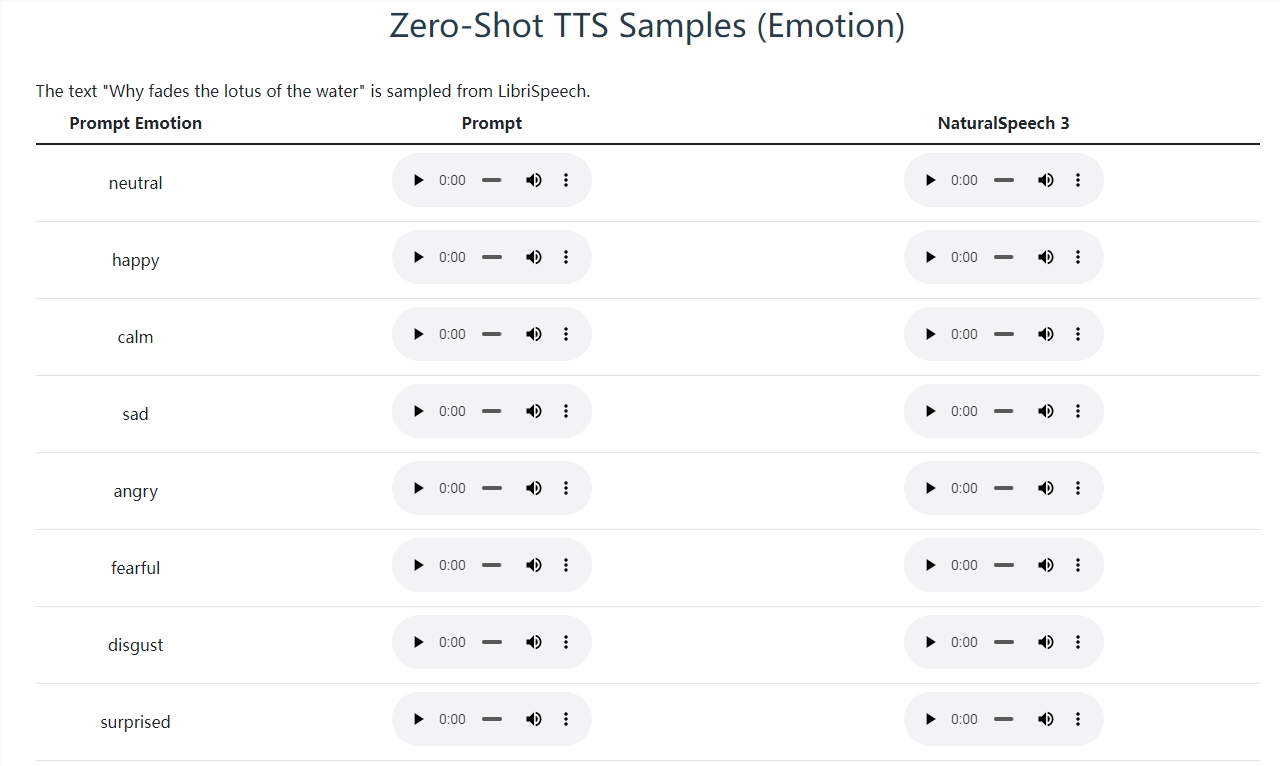
除了LibriSpeech基准测试,NaturalSpeech3还在Ravdess基准测试上表现出色。在MCD(Mel频率倒谱系数)方面,相较于其他系统,NaturalSpeech3的平均MCD显著降低,表现出更好的语音合成效果。
值得注意的是,由于该模型能够以高度相似的说话者模仿真实语音,存在潜在的滥用风险,例如欺骗语音识别或冒充特定说话者。因此,在实验中,假定用户同意成为语音合成的目标说话者。为了防止滥用,研究者呼吁开发强大的合成语音检测模型,并建立一个系统,让个体报告任何疑似滥用行为。这一研究符合微软的负责任AI原则。
项目网址入口:https://top.aibase.com/tool/naturalspeech-3
价格翻十倍的“童年顶流”,让人躺赚两万元?
童年顶流,换一个马甲重出江湖。在小红书、微博和抖音等平台上,无数年轻人晒出“人生四格”,各种拍摄教程更是层出不穷。评论区,有人好奇,“这不就是小时候拍的大头贴吗,怎么就成‘人生四格’了”?也有人给它们取了个更加通俗易懂的名字,“韩式大头贴”。童年5—15元一版的大头贴,一旦加上“韩式”两字,价格能翻到20—60元,还摇身变成了互联网上的社交货币。图源:小红书博主“一枝南南”站长网2023-10-26 09:13:170000华为 HarmonyOS 现已稳居第三大手机操作系统
在手机市场上,主要有两大操作系统,Android和iOS。尽管Tizen、KaiOS等其他系统也尝试过,但它们并没有在市场上产生太大影响。现在看来,在手机操作系统方面,市场上出现了第三股势力。站长网2023-05-23 11:12:350000小米14获抖音电商年度大奖:刷新国产智能手机销量纪录
站长之家(ChinaZ.com)1月16日消息:近日,小米官方旗舰店在社交媒体上宣布,小米14在抖音电商平台上首发,成功获得了2023抖音电商金营奖年度品牌营销大奖。据获奖理由显示,小米14首发15分钟内,抖音电商GMV(交易总额)突破了亿元大关,这一成绩刷新了抖音电商平台年度国产智能手机销量记录。。站长网2024-01-16 16:17:020000东方甄选公布董宇辉收益:不会像传统MCN拿提成 以股权绑定公司利益
快科技1月21日消息,据国内媒体报道,近日东方甄选召开临时股东大会,谈到董宇辉的收益信息。期间,东方甄选提到旗下与辉同行”直播间、主播利益分成以及未来战略等重要问题。据悉,在股东大会上,关于收益分成情况,东方甄选管理层表示,与辉同行”是东方甄选的全资子公司,保证由东方甄选100%控股。00003000万办一场演唱会,小杨哥“复刻”辛巴
“这是我参加过最好玩的演唱会,你们俩是我见过最好的主持人!”11月26日,疯狂小杨哥在合肥奥体中心举办了“小杨甄选演唱会”,大小杨兄弟俩和曾宝仪同台主持,13位明星参演,演唱会当天的直播收获了5969万观看,点赞超4亿。站长网2023-11-30 17:55:380000