通过纠正检索增强生成 (CRAG) 提高大语言模型的准确性
**划重点:**
1. 🧠 语言模型困扰准确性问题,CRAG方法通过轻量级检索评估器解决检索失败导致的生成问题。
2. 🔄 CRAG采用动态文档检索,引入分解-重组算法,确保只有最相关、准确的知识融入生成过程。
3. 📈 CRAG在短文回答和长篇传记生成等任务上 consistently 胜过标准检索增强生成方法,为语言模型精度迈出重要一步。
在自然语言处理中,追求语言模型精度的过程中,创新的方法不断涌现,以缓解这些模型可能存在的固有不准确性。其中一个显著的挑战是模型倾向于产生“幻觉”或事实错误,因为它们依赖内部知识库。这一问题在大语言模型(LLMs)中尤为明显,尽管在生成与现实事实一致的内容时,它们通常需要改进。
为了解决这个问题,引入了检索增强生成(RAG)的概念,通过在生成过程中整合外部相关知识来增强LLMs。然而,RAG的成功在很大程度上取决于检索到的文档的准确性和相关性。关键问题出现了:当检索过程失败时,引入不准确或无关信息会对生成过程产生什么影响?
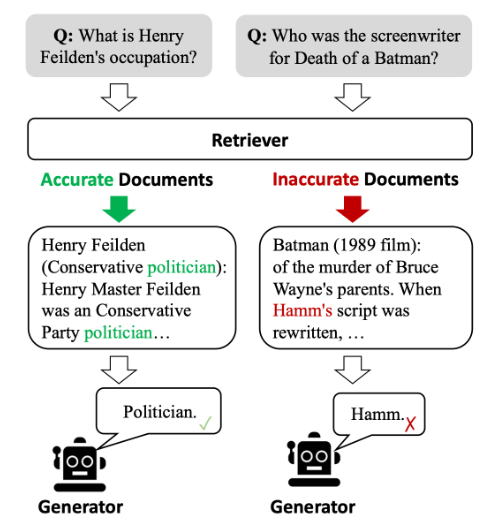
这时就出现了纠正检索增强生成(CRAG)方法,这是研究人员为了加强生成过程抵御不准确检索的陷阱而设计的一种创新方法。在核心层面,CRAG引入了一个轻量级检索评估器,这是一个用于评估给定查询的检索文档质量的机制。这个评估器是至关重要的,它提供了对检索文档相关性和可靠性的细致理解。基于其评估,评估器可以触发不同的知识检索操作,增强生成内容的强大性和准确性。
CRAG的方法在文档检索方面独具特色。当评估发现检索到的文档不佳时,CRAG不仅仅停留在承认这一事实。相反,它采用一种复杂的分解-重组算法,有选择地关注检索信息的核心,同时丢弃无用的部分。这确保只有最相关、准确的知识被融入生成过程。此外,CRAG充分利用网络的广泛性,通过大规模搜索来扩充其知识库,超越了静态、有限的语料库。这不仅拓宽了检索信息的范围,还提升了生成内容的质量。
CRAG的有效性在多个数据集上得到了严格测试,涵盖了短文和长文生成任务。结果是明显的,CRAG始终优于标准RAG方法,展示了其在导航准确知识检索和集成复杂性方面的能力。尤其在短文回答和长篇传记生成任务中,其对信息的精准度和深度尤为突出。
这些进展标志着追求更可靠、准确语言模型的一大步。CRAG通过优化检索过程,确保外部知识的高相关性和可靠性,标志着一个重要的里程碑。这种方法解决了LLMs中“幻觉”问题,为整合表面知识到生成过程中设定了新的标准。
CRAG重新定义了语言模型精度的景观。其发展突显了向生成流畅文本、并以前所未有的事实完整性进行生成的模型的关键转变。这一进展承诺提升LLMs在从自动化内容创建到复杂对话代理等应用中的效用,为语言模型可靠地反映人类知识的丰富性和准确性铺平了道路。
乌克兰人工智能法规计划将于 2024 年出台
站长之家(ChinaZ.com)10月10日消息:乌克兰计划在明年推出人工智能(AI)法规,但前提是欧洲也采取相同的举措。该国数字转型部于10月7日发布了其AI发展路线图,表示希望通过一项与欧洲联盟的AI法案类似的法律来协助企业,同时帮助公民防范AI风险。站长网2023-10-10 11:01:270001称斤卖羽绒服火上热搜,这些商家“卷疯了”,赚到钱了吗?
汤玲掏出电子秤,一连称了一个手拎包,一个腋下包,一个手拎小包,还有一个棕色的小背包。像在菜市场卖菜一样,她称完4个包包的重量,旁边的另一位主播喊了一声:“4个包包,重2.7斤,后台加一个3斤的链接!”直播间的背景板上,除了挂着满屏的包包,还有一条显眼的标语:“省下广告钱!打出真低价!包包论斤卖!”站长网2023-11-09 14:01:450000从小红书首届创作者获奖名单里,我们读到了这些信号
小红书给创作者颁奖了,我们第一时间拿到了获奖名单。从这份名单里,我们看到了一些官方说了的以及还没说的信号。8月30日,小红书举行了一场创作者开放日活动——“熟人300·创作者年度见面会”,除了公布了小红书的“熟人300”名单之外,对其中表现突出的创作者颁发的16个奖项是最大看点。站长网2024-09-03 17:07:230000苹果 Mac App Store 充斥大量虚假的付费 ChatGPT 应用
开发者和AppStore用户长期以来都一直抱怨一些应用程序提供有限的功能并高价收费,希望骗取用户的钱财,而最新的趋势是一堆ChatGPT应用程序涌入了AppStore。站长网2023-04-26 17:26:450001抖音上线“粉丝抹除、限制关注”功能
抖音今日发布了关于关于上线“粉丝抹除、限制关注”功能的公告。公告称,为规范用户行为,治理不当获取粉丝的账号,建设更加真实美好的社区生态,抖音根据《互联网用户账号信息管理规定》《抖音社区自律公约》等法律及平台规则,制定《抖音违规涨粉治理规范》,并将于2023年7月3日起正式生效。站长网2023-06-30 01:35:040001