语音大模型SpeechGPT-Gen:8B参数,零样本生成语音
划重点:
1. 📌 SpeechGPT-Gen介绍:由复旦大学研究人员推出,是一种具有语义和感知信息建模高效性的8B参数语音大型语言模型(SLLM)。
2. 📌 创新方法:采用Chain-of-Information Generation(CoIG)方法,将语音生成的语义和感知信息分离处理,解决了传统方法中的低效和冗余问题。
3. 📌 强大性能:在零样本文本到语音、语音转换以及语音对话等多个应用中,SpeechGPT-Gen展现出卓越的性能和可扩展性。
人工智能和机器学习领域中最令人兴奋的进展之一是使用大型语言模型(LLMs)进行语音生成。虽然传统方法在各种应用中表现出色,但面临一个重大挑战:语义和感知信息的整合,常常导致低效和冗余。这就是复旦大学研究人员推出的具有突破性方法SpeechGPT-Gen发挥作用的地方。
SpeechGPT-Gen采用信息链生成(CoIG)方法开发,代表了语音生成方法的重大变革。传统的语义和感知信息整合建模通常导致低效,类似于试图用宽泛、重叠的笔触绘制详细的图片。相比之下,CoIG犹如在绘画中为不同元素使用单独的刷子,确保语音的每个方面 - 语义和感知 - 都得到关注。
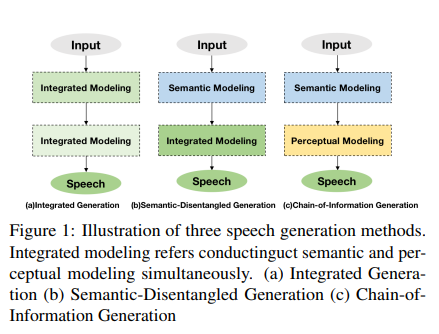
SpeechGPT-Gen的方法论在其处理上非常引人注目。它利用基于LLMs的自回归模型进行语义信息建模。该模型的这一部分处理语音的内容、含义和上下文。另一方面,使用流匹配的非自回归模型用于感知信息建模,专注于语音的细微之处,如语调、音调和节奏。这种明确的分离使得语音处理更加精细高效,显著减少了传统方法中存在的冗余。
在零样本文本到语音中,该模型实现了更低的词错误率(WER),并保持了高度的说话者相似性。这表明了其先进的语义建模能力以及保持个体声音独特性的能力。在零样本语音转换和语音对话方面,该模型再次展示了其卓越性能,相较于传统方法在内容准确性和说话者相似性方面更胜一筹。这一多样应用中的成功展示了SpeechGPT-Gen在实际场景中的实际效果。
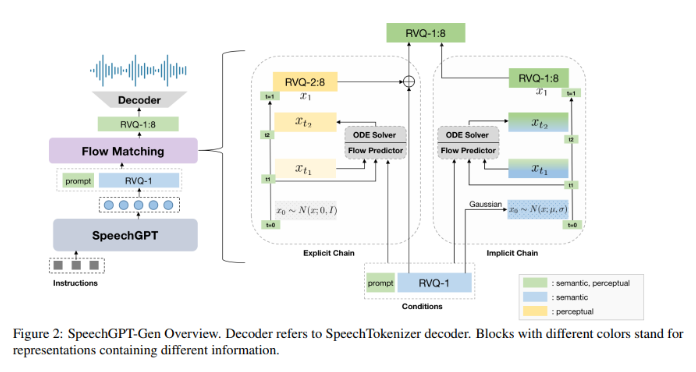
SpeechGPT-Gen一个特别值得注意的方面是其在流匹配中使用语义信息作为先验的创新。这种创新相较于标准的高斯方法标志着对模型在从简单先验分布到复杂实际数据分布进行转换效率的显著改善。这种方法不仅提高了语音生成的准确性,还有助于合成语音的自然度和质量。
SpeechGPT-Gen表现出色的可扩展性。随着模型规模和处理的数据量增加,它不断减少训练损失并提高性能。这种可扩展性对于使模型适应各种需求至关重要,确保在应用范围扩大时它仍然有效而高效。
总的来说,研究可以简洁概括为:
1. SpeechGPT-Gen解决了传统语音生成方法中的低效问题。
2. Chain-of-Information Generation方法分离了语义和感知信息处理。
3. 该模型在零样本文本到语音、语音转换和语音对话中展现出卓越的结果。
4. 在流匹配中使用的语义信息提升了模型的效率和输出质量。
5. SpeechGPT-Gen表现出色的可扩展性,对于适应不同应用至关重要。
项目入口:https://top.aibase.com/tool/speechgpt
论文:https://arxiv.org/abs/2401.13527v2
小红书博主晒老鼠跳舞获赞1万 原来是用了Animate Anyone
小红书博主“小幸怡子”养了一只可爱的鼠鼠叫布丁,平时会晒晒它吃饭、玩耍等日常活动的照片,突然有一天,布丁像人一样跳起舞来,吸引了1万余人点赞。只见布丁举起双手,摆动着身体,配合着歌词叉腰、扭一扭,评论区的猫猫都看呆了。博主惊讶地说道:“表情完全变了,一点不像布丁了。”站长网2024-01-22 14:26:280002中国高科集团与百度智能云合作 前者旗下应用引入文心大模型
近日,中国高科集团与百度智能云正式签署战略合作协议,双方将围绕“生成式大模型、公有云服务、产教融合”等方面开展深入合作,进一步推动人工智能前沿技术赋能。据介绍,中国高科集团和百度智能云此次合作将按照“生成式大模型、公有云服务、产教融合”三大方向展开。首先,在大模型方向,双方将基于文心大模型并结合高科集团自身业务展开生成式大模型深入合作,聚焦知识管理、智能客户、数字人直播、智能营销等方面。站长网2023-07-18 12:30:480000MyShell AI开发高质量语音合成工具MeloTTS 支持中英混合发音
MeloTTS是由MyShellAI开发的一个高质量的多语言文本到语音(TTS)库。这个库支持英语、西班牙语、法语、中文、日语和韩语等多种语言,使其在全球范围内具有广泛的应用价值。项目地址:https://top.aibase.com/tool/melotts站长网2024-02-27 11:10:360006OpenAI宣布年收入达13亿美元 每月入账1亿刀
要点:1.OpenAI的年收入在2023年达到了13亿美元,每月平均收入超过1亿美元,年同比增长超过4500%。2.谷歌DeepMind在2022年的收入同比下滑21%,利润下滑近40%,业绩下滑表现不佳。3.OpenAI计划举行首届开发者大会,着重优化成本,并计划募资多至1000亿美元,展望光明的前景。站长网2023-10-13 14:21:070000德国将对OpenAI的ChatGPT数据使用情况展开调查
继意大利,德国数据保护机构现在也正在加强对ChatGPT的监管,德国联邦州数据保护专员们同启动了相应的行政程序。德国AI工作组负责人迪特·库格尔曼表示,“如果使用个人数据,包括作为AI的训练数据,必须有法律依据,我们必须知道数据来自何处。”站长网2023-04-21 11:55:540000