字节推多模态理解和图像定位模型LEGO 具备精准定位的能力
站长网2024-01-15 15:25:552阅
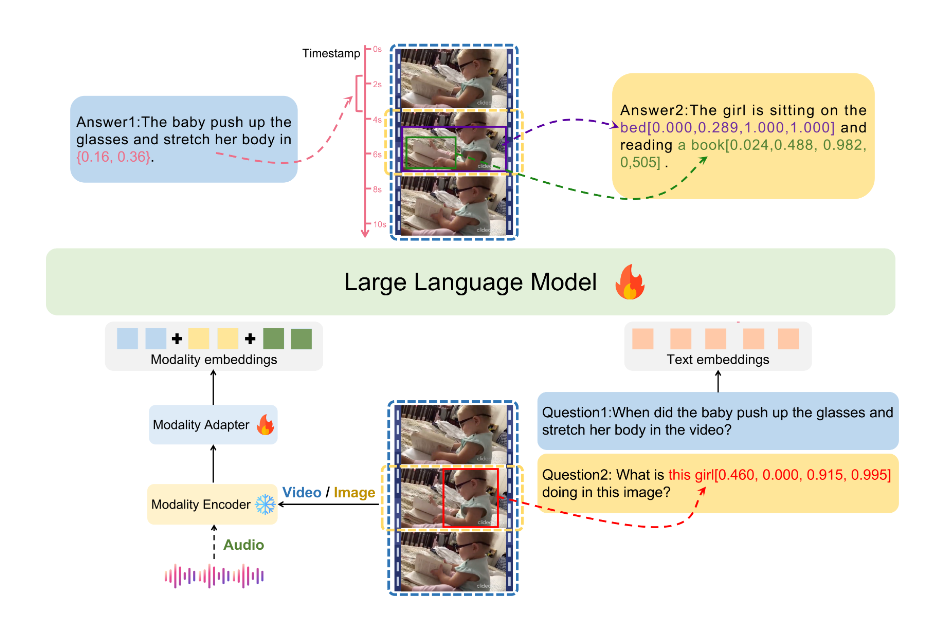
LEGO是一个由字节跳动和复旦大学联合研发的多模态理解和图像定位模型。这一模型具有处理和理解多种类型的输入的能力,包括图像、音频和视频。同时,LEGO还具备精准定位的能力,能够在图像中标识出物体的具体位置,在视频中指出特定事件发生的时间点,在音频中识别出特定声音的来源。
该模型的主要功能特点包括多模态理解、强大的定位能力、构建高质量数据集、应对复杂任务、广泛的应用潜力以及实时处理和响应。LEGO模型可以处理包含多个元素和复杂指令的任务,根据详细的描述或指令来分析和解释内容,提供准确的输出。
项目地址:https://lzw-lzw.github.io/LEGO.github.io/
由于其多模态理解和定位的能力,LEGO模型适用于广泛的应用场景,包括内容创作、教育、娱乐、安全监控等领域。此外,LEGO模型还能够快速处理输入并生成响应,适用于需要实时分析和反馈的应用场景。
LEGO项目的工作原理包括对多种模态数据的处理、特征提取、融合和上下文分析,最终根据用户的需求生成精确的定位和响应。模型首先处理多种类型的输入数据,包括图像、音频和视频,并进行解析和预处理以适合进一步的分析。
然后,模型提取每种输入数据的关键特征,并将这些特征进行融合,形成一个统一的、多层次的理解。接下来,模型分析整合后的数据以及相应的上下文信息,最终根据用户的指令或查询进行定位和响应,并生成相应的输出结果。
LEGO模型的研发和应用将为多模态理解和图像定位领域带来重大的突破,为相关领域的发展提供新的思路和解决方案。
0002
评论列表
共(0)条相关推荐
重拳出击!抖音2024年封禁110万个水军账号 协助抓捕90名犯罪嫌疑人
快科技1月26日消息,今日,抖音发布2024年平台治理报告,抖音表示,在创新规则、打击违规行为、强化用网安全保障等方面推出了一系列举措。其中包括,发布AI虚拟人物治理规范,建立热点事件核实机制,推出剧情演绎标注工具,溯源打击伪成功学”、网络水军等违规内容。据抖音介绍,无底线博流量”虚假摆拍”不当利用AI生成内容”是用户反馈较为集中的问题领域。站长网2025-01-27 10:36:040000海外版拼多多“Temu”,会成为下一个TikTok吗?
找人“砍一刀”在美国火了!有没有搞错?美国人民都疯了吗?大家千万别误会,此一刀非彼一刀,今天要讲的这个“砍一刀”是大家十分熟悉的一款“中国制造”APP—拼多多!在很多人心目中,美国GDP长期占据世界榜首,加上只有3亿多人口,大家生活一定过得很滋润吧?而拼多多,那不是我等发展中国家平民百姓用的?怎么还能上得了美利坚人民的“大雅之堂”?站长网2023-04-14 17:01:230005陈香贵开始猛扑抖音同城
抖音同城在今年已经成为餐饮界热议的话题。而去年抖音的同城生活部门还在小步摸索,今年就异军突起,甚至打破了传统同城“人货场”模式,开创了一条全新的内容型同城电商新赛道。背后的逻辑是,传统本地生活电商平台,如阿里、美团和大众点评,流量主要局限在周围3公里范围内。抖音则利用内容的先天优势,将广告型内容巧妙融入用户时间,通过创意而有趣的内容激发用户兴趣,再通过优惠券进行转化交易。站长网2023-08-26 17:25:460000三星Exynos 2500芯片确认于2025年下半年推出:性能不及骁龙8 Elite
快科技2月1日消息,三星的财报电话会议,三星系统LSI部门在会议中透露了Exynos2500的相关信息,确认正在研发这款芯片,并计划在2025年下半年推出。据透露,Exynos2500芯片将首次搭载在三星的折叠屏手机上,包括GalaxyZFold7和ZFlip7。0000特斯拉 2023年Q3财报:大举投资人工智能,保持持有比特币
划重点:特斯拉在Q32023继续保留其大额比特币投资,价值1.84亿美元,超过了2021年首次购买的15亿美元比特币的一部分。公司大举投资人工智能项目,计算能力翻倍增加,专注于人工智能的发展,而非编码软件。尽管财报显示总营收增长9%,但营收和利润低于市场预期,特斯拉的股价下跌。站长网2023-10-19 11:18:020000













