南大提出全新框架VividTalk 一张照片一段声音秒生超逼真视频
要点:
南大等机构研究人员提出的通用框架,名为VividTalk,能通过一段音频和一张照片生成高质量、富有表现力的说话视频,实现口型和音频的无缝对齐。
框架采用两阶段生成,第一阶段考虑面部运动和blendshape分布之间的映射,利用多分支Transformer网络建模音频上下文,第二阶段渲染内外表面的投影纹理,实现全面建模运动。
VividTalk在实验中展现出优越的生成质量和模型泛化性,支持多语言,能够生成具有丰富表情和自然头部姿势的口型同步头部说话视频。
近日,南大等机构的研究人员推出了一项引人注目的研究成果——VividTalk框架,其能够通过一段音频和一张照片实现令人惊叹的说话视频生成。这一通用框架采用了两阶段生成方法,首先通过考虑面部运动和blendshape分布之间的映射,利用多分支Transformer网络建模音频上下文,生成3D驱动的网格。

论文地址:https://arxiv.org/pdf/2312.01841.pdf
框架的第一阶段注重嘴唇运动和面部表情的生成,使用blendshape和顶点偏移作为中间表征,以提供全局粗略的面部表情运动和局部细粒度的嘴唇运动。为了更合理地学习刚性头部运动,研究人员巧妙地将问题转化为离散有限空间中的代码查询任务,并构建了可学习的头部姿势代码本。这一创新性的方法使得从音频到头部姿势的学习变得更加准确和高效。

第二阶段则在生成器中使用了双分支motionvae来建模2D密集运动,通过投影纹理表示在2D域中进行运动转换,提高了网络性能和生成视频的质量。VividTalk框架在实验中取得了显著的成果,能够生成具有表情丰富、自然头部姿势的口型同步视频。实验数据集的丰富性和优化的训练方法使得该框架在生成质量和模型泛化方面表现优越。
这一框架的推出代表了在语音合成领域的一次重要突破。VividTalk不仅支持多语言,而且在生成效果上也胜过了其他同类方法。这项研究成果将有望在虚拟人物、语音合成和视频制作等领域产生深远的影响。
阿里研究部门推出了专为东南亚量身定制的AI大模型SeaLLM
划重点:⦁阿里巴巴推出了首个针对东南亚市场定制的大型语言模型AI,将东南亚视为重要增长市场⦁东南亚语言模型在语言和安全任务方面表现优异,超过其他开源模型⦁大数据公司依然在积极发展由OpenAI的ChatGPT带来的生成式AI浪潮,大力投入相关技术的发展0000LLaMA 2:如何立即访问和使用 Meta 最新多功能开源聊天机器人
Facebook的母公司Meta本周在人工智能(AI)行业掀起了波澜,推出了LLaMA2,这是一个开源的大型语言模型(LLM),旨在挑战大型科技竞争对手的限制性做法。与谷歌、OpenAI和其他公司发布的严格保密的专有模型不同,Meta公司自由发布LLaMA2背后的代码和数据,以便全球研究人员能够构建和改进这项技术。站长网2023-07-21 15:17:280000AI视野:Meta发布Code Llama70B;Nijijourney V6模型正式上线;Chrome将内置AI写作助手;Minimax的AI对话机器人海螺问问上线
欢迎来到【AI视野】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/🤖📱💼AI应用Meta发布最新AI编程工具CodeLlama70B【AiBase提要:】1.Meta发布了CodeLlama70B。站长网2024-01-30 16:06:340000马斯克威胁将起诉微软涉嫌非法使用Twitter数据训练AI模型
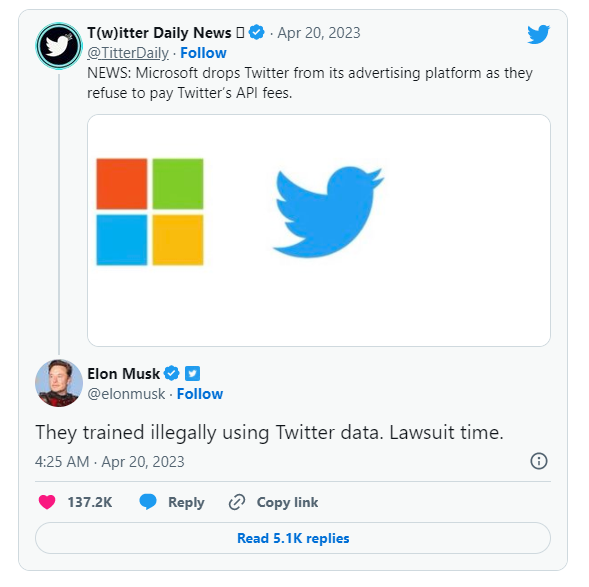
特斯拉CEO马斯克在推特上威胁将起诉微软,指责其使用Twitter数据训练其人工智能模型。许多大科技公司正在开发最新的AI模型,需要大量数据进行训练,而拥有这些数据的人开始提出要求。像GPT这样的LLM需要数TB的数据用于训练,其中大部分数据是从Reddit、StackOverflow和Twitter等网站上收集的。站长网2023-04-20 10:25:310000价格更低!比亚迪海豚荣耀版上市官宣:内外都有新配色
快科技2月20日消息,据比亚迪汽车官方,旗下纯电动轿车海豚荣耀版将于本月23日上市。该车位小型纯电车,长宽高分别为4125/1770/1570mm,但得益于纯电平台,轴距达到了惊人的2700mm,新款车型外观变化不大,新车将拥多项升级,新增亚特兰蒂斯灰、热浪绯红纯色外观,并提供全新五孔花鳍轮毂。0000