北大提出统一的视觉语言大模型Chat-UniVi 3天训练成果惊艳众人
要点:
北大和中山大学研究者提出的Chat-UniVi是一种统一的视觉语言大模型,能够在统一的视觉表征下同时处理图片和视频任务,且仅需三天训练即可获得130亿参数的通用视觉语言大模型。
Chat-UniVi采用动态视觉token来统一表示图片和视频,通过最近邻的密度峰聚类算法获取动态视觉token,多尺度表征提高了模型的性能,使其在图片和视频的各种任务中取得卓越性能。
Chat-UniVi在图片、视频理解以及问答任务等多个实验中表现卓越,使用更少的视觉token达到了与其他大模型相媲美的性能水平,同时开源了代码、数据集和模型权重。
近日,北京大学和中山大学等机构的研究者提出了一种名为Chat-UniVi的视觉语言大模型,实现了统一的视觉表征,使其能够同时处理图片和视频任务。这一框架的独特之处在于,它不仅在深度学习任务中表现卓越,而且仅需短短三天的训练时间,就能够训练出具有130亿参数的通用视觉语言大模型。

项目地址:https://github.com/PKU-YuanGroup/Chat-UniVi
Chat-UniVi的核心方法是采用动态视觉token,通过最近邻的密度峰聚类算法来获取这些动态token。这一方法极大地减少了视觉token的数量,降低了模型的训练和推理成本。研究人员通过实验证明,Chat-UniVi在图片理解、视频理解、问答等多个任务中都表现出色,甚至在较小的参数量下也能超越其他大型模型。
文章还详细介绍了Chat-UniVi的训练过程,分为多模态预训练和联合指令微调两个阶段。这一两阶段的训练策略使得模型能够在混合数据集上进行训练,无需对模型结构进行修改,展现了其在多任务学习上的灵活性和高效性。
Chat-UniVi的成功实验结果包括在图片理解、视频理解、问答等多个任务中都超越了先进的方法。而其在幻觉评估上的优越性更是引人注目,证明了采用动态视觉token和多尺度表征的有效性。
综合而言,Chat-UniVi的提出为视觉语言模型的研究领域带来了新的思路,通过统一的视觉表征实现了对多模态数据的高效处理,为深度学习模型的训练和推理提供了更加便捷和经济的解决方案。
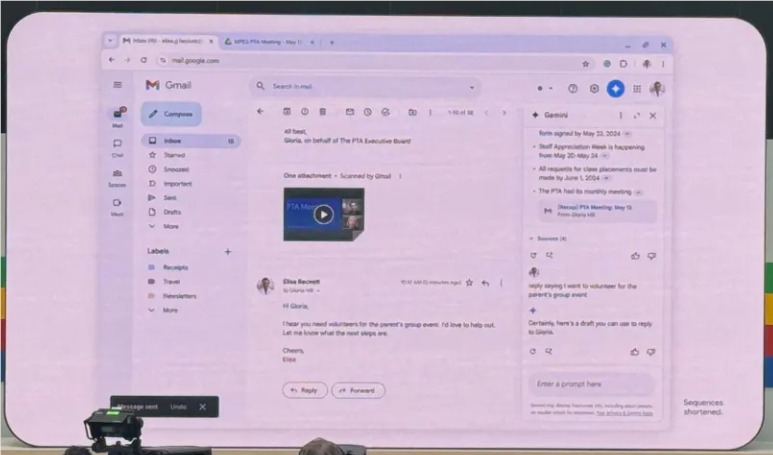
Gmail引入Gemini AI技术,帮助用户搜索、总结和起草邮件
划重点:-Gmail用户将能够利用GeminiAI技术搜索、总结和起草邮-Gemini能够处理更复杂的任务,如帮助处理电子商务退货,搜索收件箱、查找收据并填写在线表格-Gemini还能够分析附件,并提供邮件摘要和关键要点站长网2024-05-15 14:18:110000抖音本地生活的流量富矿,才挖了一尺
2023年的主题毫无疑问是消费。出行管控的放开,线下海量客流的回归,正在催生一轮轮消费浪潮涌向实体门店。而那些最强劲的风潮,往往从抖音发端。这两天,瑞幸联名茅台的新品酱香拿铁席卷了全网,抖音则是酱香拿铁热度传播的核心阵地。根据瑞幸官方数据,酱香拿铁在抖音的首发专场直播,用4个小时卖出了超1000万销售额。从9月1日到9月4日,瑞幸咖啡在抖音平台新增了100万用户。站长网2023-09-09 11:35:460001ChatGPT+小红书爆文,1天量产100篇笔记
│前言│随着AI技术的不断发展,它已经逐渐渗透到了我们的生活之中,包括内容营销领域。我们通过AI算法生成文本、优化搜索引擎排名、提高用户体验等,现在AI已逐渐在改变时代的进步,AI也将成为下一个十年的一个变革。我们每个创业者、内容创作者以及普通人都要学会驾驭AI。ChatGPT是一款基于GPT-3.5架构的大型语言模型,可以生成自然语言文本、进行语言理解、问答等任务。站长网2023-05-17 09:49:150000SDK工具包Observe:可持续监控WebAssembly代码
Observe是一个用于WebAssembly的可观测性SDK工具包,它可以持续监控WebAssembly代码在运行时的执行情况。该库包含所需的运行时SDK和适配器,以实现对WebAssembly的实时性能分析和追踪,未来它将成为一个完整的WebAssembly可观测性栈。项目地址:https://github.com/dylibso/observe-sdk主要特性:站长网2023-08-31 11:00:110000AI视野:文心一言软件著作权获批;万兴科技发布大模型 “天幕”;Bing Chat确认100%采用GPT-4
📰🤖📢AI新鲜事百度文心一言软件著作权获批9月13日,百度“文心一言软件”著作权获批,8月31日向全社会开放,用户可以在应用商店下载使用。要点:1.9月13日,百度“文心一言软件”著作权获批,当前版本为V1.0.0。2.8月31日,百度文心一言APP向全社会开放,用户可以下载APP或访问官网使用。3.文心一言开放后迅速成为应用商店下载榜首,是首个中文AI原生应用登顶。站长网2023-09-18 15:48:570000