当韩国女团BLACKPINK进军二次元,清华叉院AI神器原来还能这么玩
如果你手机里有一些修图软件,你可能用过里面的「AI 绘画」功能,它通常会提供一些把照片转换为不同风格的选项,比如动漫风格、写真风格。但如今,视频也可以这么做了:



这些动图来自 X 平台(原推特)网友 @CoffeeVectors 生成的一段视频。他把韩国女团 BLACKPINK 代表作《DDU-DU DDU-DU》的原版 MV 输入了一个 AI 工具,很快就得到了动漫版的 MV。

这个视频是借助一个名叫 ComfyUI 的工具来完成的。ComfyUI 是一个开源的基于图形界面的 Workflow 可视化引擎,用于被广泛采用的文生图 AI 模型 Stable Diffusion。它提供了一个用户友好的图形界面,可以将多个 Stable Diffusion 模型及其 Hypernetwork 组合成一个完整的工作流(Workflow)实现自动化的图像生成和优化。同时,社区也开发了各种 ComfyUI 的扩展插件,可以进一步增强其功能。
作者 @CoffeeVectors 表示,在制作这个 MV 的过程时,他在 ComfyUI 中用到了 AnimateDiff 和 multi-controlnet 工作流,前者用于动漫风格的生成,后者用来实现生成效果的控制。更重要的是,他在这次工作流中引入了一个当下很火的神器 ——LCM LoRA。
在《实时文生图速度提升5-10倍,清华 LCM/LCM-LoRA 爆火,浏览超百万、下载超20万》一文中,我们已经介绍过,LCM 是清华大学交叉信息研究院的研究者们构建的一个新模型,它的特点是文生图、图生图的效果都非常快,可以根据你的文字指令或草图指示实时生成新图。
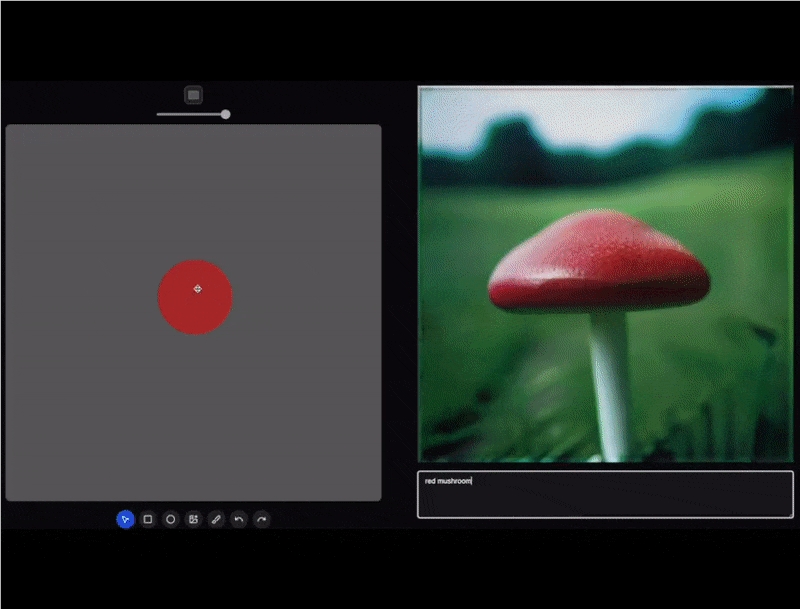
在此基础上,研究者们又进一步开发了 LCM-LoRA,可以将 LCM 的快速生成能力在未经任何额外训练的情况下迁移到其他 LoRA 模型上。由于效果非常惊艳,模型在 Hugging Face 平台上的下载量已超20万次,X 平台上到处都能看到利用 LCM-LoRA 生成的实时视频效果(如下方的视频所示)。
机器之心机动组,赞90
那么,这个动漫版的 MV 是怎么做的呢?@CoffeeVectors 在帖子中详细描述了他的做法。
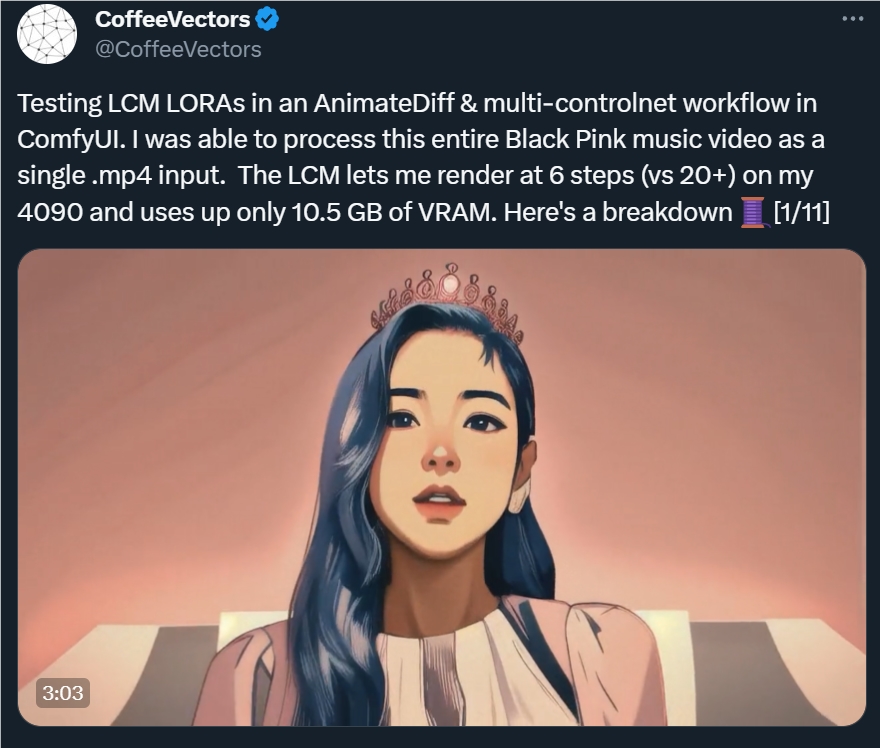
在下载了原版 MV 视频后,@CoffeeVectors 将 BLACKPINK 的整个 MV 作为单个 .mp4输入进行处理。LCM 可以让他在4090上通过6步进行渲染(之前需要20多步),而且只占用10.5GB 的 VRAM。以下是详细数据:
整个渲染过程耗时81分钟,共2,467帧,每帧大约花2秒。这不包括从视频中提取图像序列和生成 ControlNet 映射的时间。在 SD1.5版中使用 Zoe Depth 和 Canny ControlNets,分辨率为910x512。
要改进输出效果,使其风格更鲜明、细节更丰富、感觉不那么像一帧一帧的转描动画,就需要对单帧画面进行调整。但是,一次性完成整个视频,可以为你提供一个粗略的草稿,以便在此基础上进行迭代。
对于输入视频,他每隔一帧选取一帧,以达到12帧 / 秒的目标。

这是 @CoffeeVectors 添加 LCM LoRA 的截图。他选择了检查点中内置的 VAE:
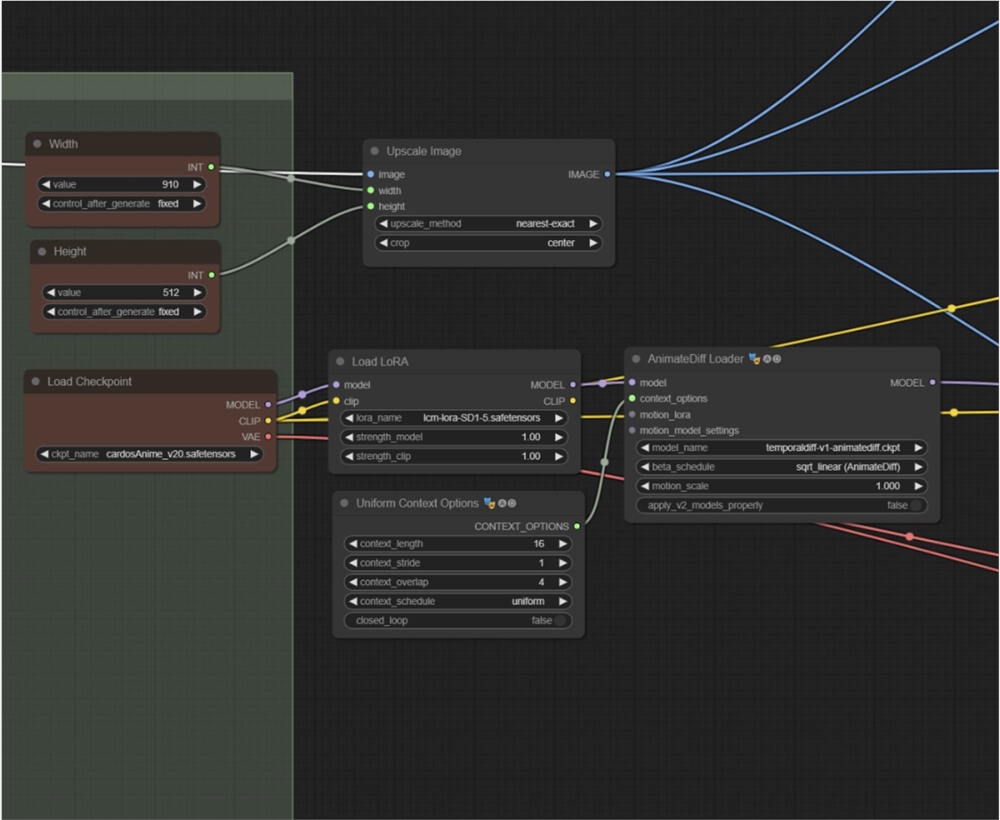
他把提示写得很泛,想看看这个提示在各种镜头中的适配效果怎么样。

在 K 采样器中,他使用了 LCM 采样器。注意,你需要更新到最新版本的 ComfyUI 才能用这个采样器。
下图描述了 @CoffeeVectors 如何安排 multi-control net 的节点:

最后,@CoffeeVectors 还推荐了一些相关教程:
视频教程:https://www.youtube.com/watch?app=desktop&v=zrxd95Mxz24
技术博客:https://huggingface.co/blog/lcm_LoRA
对这类技术应用感兴趣的开发者们可以玩起来啦!
外媒如何报道GPT-4o,有没有“炸裂”?
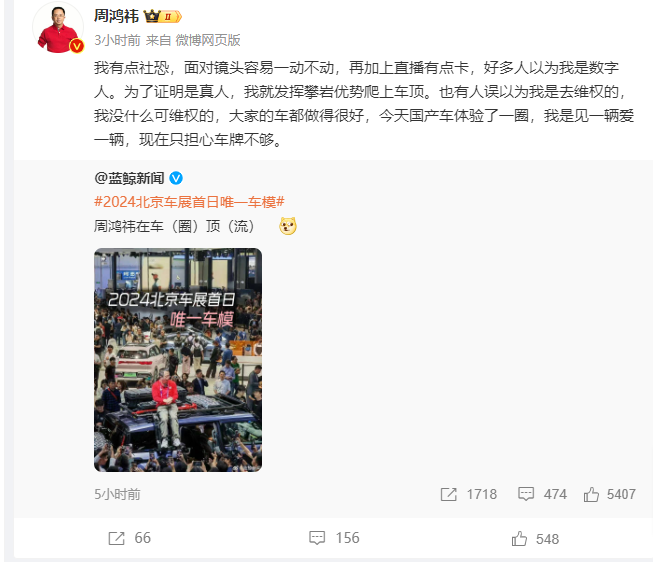
今日凌晨,OpenAI宣布推出GPT-4o。该模型是GPT-4型号的更新版本,将向免费客户开放。据介绍,GPT-4o(“o”代表“omni”)。它可以实现文本、音频和图像的任意组合作为输入,并生成文本、音频和图像输出的任意组合。且有诸多惊艳应用:这确实是一项很棒的更新升级,推动了人工智能技术进一步发展。站长网2024-05-15 17:48:450000周鸿祎北京车展上演爬车顶 竟是想证明自己不是数字人
划重点:⭐️周鸿祎为证明自己是真人而非数字人,爬上车顶⭐️周鸿祎幽默解释爬车顶行为,遭遇误解和调侃⭐️周鸿祎展示攀岩优势,成为北京车展焦点人物2024年北京车展开幕首日,360集团创始人周鸿祎以一场惊喜亮相成为车展焦点。他穿着鲜艳的红衣,攀上了一辆猛士917的顶部,成为全场瞩目的对象。站长网2024-04-26 04:35:240000孩子王KidsGPT智能顾问已通过APP、小程序等上线
孩子王表示,KidsGPT智能顾问已在六一童玩节期间通过孩子王APP、小程序、企微社群等上线应用。未来公司继续加大AI投入,积极探索KidsGPT相关创新产品。据介绍,通过KidsGPT,孩子王将为6000万会员提供更高维、更新颖的数字化体验。站长网2023-06-07 19:12:140000OpenAI 的 ChatGPT 生成程序代码并不安全 但未能提醒用户
OpenAI的聊天机器人大型语言模型ChatGPT,不仅会产生不安全的代码,而且尽管其能够指出自身的缺陷,但却未能提醒用户注意其不足之处。在针对大型语言模型可能性和限制的学术兴趣狂潮中,加拿大魁北克大学的四位研究者深入探讨了来自OpenAI的ChatGPT生成的代码的安全性。站长网2023-04-23 09:32:290000iPhone 15屏幕维修费用公布 无AppleCare+最高自费超3千
站长之家(ChinaZ.com)9月18日消息:iPhone15系列手机已开始预订,苹果也在官网公布了最新一代iPhone的维修费用。数据显示,如果没有购买AppleCare保险服务,iPhone15系列手机屏幕维修的自费费用最高可达3198元。站长网2023-09-18 11:28:560002