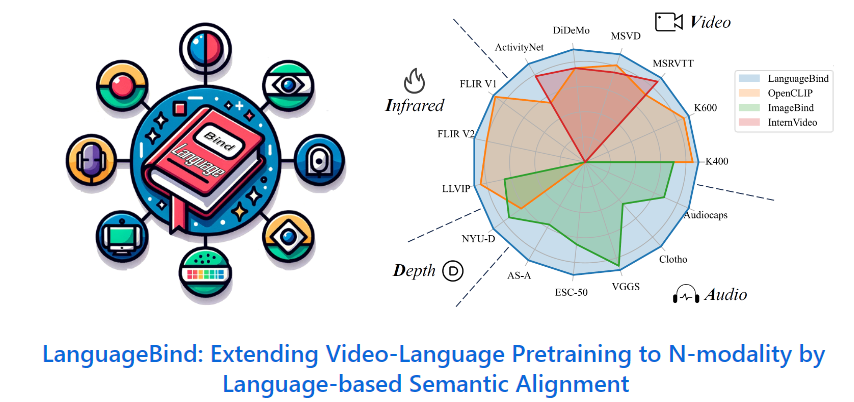
北大腾讯提出多模态对齐框架LanguageBind
要点:
1、北京大学与腾讯等机构研究者提出了多模态对齐框架LanguageBind,并在多个榜单中取得了优异表现。
2、多模态信息对齐面临挑战,需要将不同模态信息进行整合与对齐,而新框架通过语言作为中心通道实现了多模态信息的语义对齐。
3、研究团队构建了VIDAL-10M数据集,这是一个大规模、多模态数据对的数据集。
北大腾讯等提出了多模态对齐框架LanguageBind,这一新框架在多个榜单中获得卓越表现。在现代社会,信息传递和交流不再局限于单一模态,而是多模态的。由于信息交互的复杂性,如何让机器理解和处理多模态的数据成为人工智能领域的前沿问题。
当前主流的对齐技术通常会导致性能次优化,因此北大腾讯的研究团队提出了一种新的多模态对齐框架——LanguageBind,该框架利用语言作为不同模态信息对齐的纽带。在这个框架下,语言不再是附属于其他模态的标注或说明,而是成为了联合不同模态的中心通道。
项目地址:https://github.com/PKU-YuanGroup/LanguageBind
并通过将所有模态的信息映射到一个统一的语言导向的嵌入空间,实现了不同模态之间的语义对齐。该框架还构建了VIDAL-10M数据集,包含了视频 - 语言、红外 - 语言、深度 - 语言和音频 - 语言配对,以确保跨模态的信息是完整且一致的。在多模态信息处理领域,LanguageBind的提出为多模态预训练技术的发展奠定了坚实基础。
该框架摒弃了依赖图像作为主导模态的传统方法,而是直接利用语言模态作为不同模态之间的纽带。通过一系列优化的对比学习策略,LanguageBind实现了直接的跨模态语义对齐。这种方法避免了通过图像中介可能引入的信息损失,提高了多模态信息处理的准确性和效率。
此外,该研究团队构建了VIDAL-10M数据集,这是一个大规模、包含多模态数据对的数据集,涵盖了视频 - 语言、红外 - 语言、深度 - 语言和音频 - 语言等数据对。并经过了精心的质量筛选,确保了数据集的高品质和高完整性。这一举措为跨模态预训练领域提供了一个高质量的训练基础。对于多模态对齐框架LanguageBind的提出,有望为多模态学习领域带来重要的进展和突破。
MIT与Adobe联手开发DMD:生成图像质量媲美Stable Diffusion ,速度快30倍
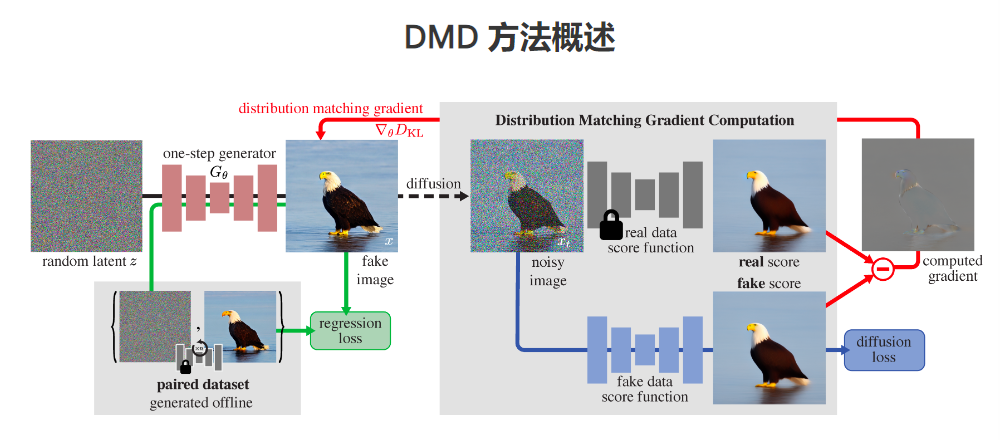
**划重点:**1.🔄**创新方法:**研究团队提出了分布匹配蒸馏(DMD)方法,将扩散模型转化为一步图像生成器,在保持图像质量的同时显著减少神经网络评估次数。2.🌐**数据优化:**通过对文本到图像数据进行精细调整,研究团队成功解决了在通用文本到图像数据上扩大模型的难题,实现了高效的图像生成。站长网2023-12-07 11:53:120000谷歌与Singular Computing达成AI专利纠纷和解
谷歌刚刚和一家人工智能技术专利诉讼的对手达成了数十亿美元的和解。这家硬件和软件开发公司SingularComputing从谷歌那里获得了一笔未公开的和解金,这结束了Singular的创始人JosephBates博士对谷歌提起的长达五年的联邦法院专利侵权案。站长网2024-01-29 15:47:170000“仅退款”成标配,谁赞成,谁反对?
这两天,#仅退款动了谁的奶酪#登上了微博热搜,引发了1.3亿阅读,1.8万讨论。“仅退款”的出现,本质上是为了减少商家和用户在关乎质量和退货问题上的争执和矛盾,也是对用户权益的保障。如今已经成为电商平台应对某些特殊情况的标配。站长网2024-07-11 20:24:200000三星Galaxy S24系列中国新品发布会今晚举行 国行价格即将公布
今晚(1月25日)19:00,三星将在中国举行GalaxyS24系列新品发布会,正式公布新机的国行价格。此前,三星已在海外发布了GalaxyS24系列手机,而国行的先行者价格也已经公布。GalaxyS24系列包括GalaxyS24、GalaxyS24和GalaxyS24Ultra三款机型。站长网2024-01-25 17:14:180000哈佛大学下学期将测试使用AI讲师来向学生授课
哈佛大学的一门受欢迎的入门级编程课程CS50将于今年秋季由人工智能教师授课。据了解,CS50的教授DavidMalan表示:“我们的希望是,通过人工智能为他们提供基于软件的工具,实现CS50课程一对一教学,每天24小时支持他们的学习,以最适合他们个人的速度和风格。”站长网2023-06-30 19:36:100000