研究警告:到2026年,AI训练数据可能告急
划重点:
1. 高质量数据对AI至关重要:强大、准确和高质量的AI算法需要大量高质量的数据来进行训练。
2. AI数据可能告急:研究人员预测,如果当前的AI训练趋势继续下去,高质量文本数据可能在2026年之前告急,而低质量的语言数据和图像数据也将在未来告急。
3. 解决数据短缺问题的方法:为了解决数据短缺问题,AI开发人员可以改进算法,更有效地利用已有数据。此外,他们可以使用AI生成合成数据来训练系统,以适应特定的AI模型。
随着人工智能(AI)达到巅峰,研究人员警告称,AI行业可能会面临训练数据告急的问题,这是强大AI系统的燃料。这可能会减缓AI模型的增长,特别是大型语言模型,并可能改变AI革命的轨迹。
为了训练强大、准确和高质量的AI算法,我们需要大量数据。例如,ChatGPT是基于570千兆字节的文本数据(大约3000亿字)进行训练的。类似地,stable diffusion算法(驱动许多AI图像生成应用,如DALL-E、Lensa和Midjourney)是基于包含58亿图像-文本对的LIAON-5B数据集进行训练的。如果算法的训练数据不足,将会产生不准确或低质量的输出。因此,训练数据的质量同样重要。低质量数据,如社交媒体帖子或模糊照片,容易获取,但不足以训练高性能的AI模型。

图源备注:图片由AI生成,图片授权服务商Midjourney
AI行业一直在不断扩大数据集的规模,这就是为什么我们现在拥有高性能模型,如ChatGPT或DALL-E3。与此同时,研究显示,用于训练AI的在线数据库增长速度远远慢于AI所需的数据集。在去年发表的一篇论文中,一组研究人员预测,如果当前的AI训练趋势继续下去,我们将在2026年之前用尽高质量文本数据,而低质量的语言数据将在2030年至2050年之间耗尽,低质量的图像数据将在2030年至2060年之间告急。尽管AI有望在未来几年内更有效地利用已有数据来训练高性能AI系统,从而降低数据需求,但数据短缺问题仍需解决。
如何解决数据短缺问题?
虽然上述问题可能让一些AI爱好者感到担忧,但情况可能没有看上去那么糟糕。关于AI模型未来的发展,还有许多未知因素,但有一些方法可以解决数据短缺的风险。一种机会是让AI开发人员改进算法,使其更有效地利用已有数据。未来几年内,他们有望能够使用更少的数据和可能更少的计算能力来训练高性能AI系统,这也将有助于减少AI的碳足迹。
另一种选择是使用AI来生成合成数据以训练系统。换句话说,开发人员可以简单地生成他们需要的数据,以适应其特定的AI模型。已经有几个项目正在使用合成内容,通常是从数据生成服务中获取的,这将在未来变得更加普遍。
开发人员还在寻找在线空间以外的内容,如大型出版商和离线存储库中的内容。想象一下在互联网之前出版的数百万篇文本,如果以数字形式提供,它们可能为AI项目提供新的数据来源。例如,新闻集团(News Corp)是全球最大的新闻内容所有者之一,最近表示正在与AI开发人员洽谈内容交易。这些交易将迫使AI公司为训练数据付费,而他们迄今大多免费从互联网上获取数据。内容创作者已经抗议允许未经授权使用其内容来训练AI模型,一些公司如微软、OpenAI和Stability AI已被起诉。获得对其工作的报酬可能有助于恢复创意工作者和AI公司之间存在的一些权力失衡。
抖音正式上线AI创作功能 最新AI特效破6亿次播放
12月10日,抖音上的博主“若若跑的贼快”发布了一条令人印象深刻的视频,庆祝粉丝数突破千万。视频中,博主在镜头前亮相,突然发生了一个丝滑的转场,使真人形象瞬间变成了漫画形象。接着,博主抱起一只猫,再次发生转场,奇迹般地,一人一猫都变成了漫画形象。这段创意十足的视频截至目前已获得超过182万次赞和12万次转发。令人惊叹的是,在评论区,博主透露这些漫画形象是通过AI生成的,而非手绘。站长网2023-12-12 14:37:090000苹果计划2027年前让9款产品全面采用OLED屏幕
据韩媒报道,苹果计划在2027年前,让其产品线中的9款设备全面转为采用OLED屏幕。报道称,苹果将在明年推出两款OLED屏幕的iPadPro,2026年将OLED屏引入iPadmini和iPadAir系列。iPadAir的屏幕尺寸保持在10.9英寸,而iPadmini将从8.3英寸升级至8.7英寸。站长网2023-11-18 13:47:340000用自己照片被告侵权还遭索赔!摄影师戴建峰起诉视觉中国
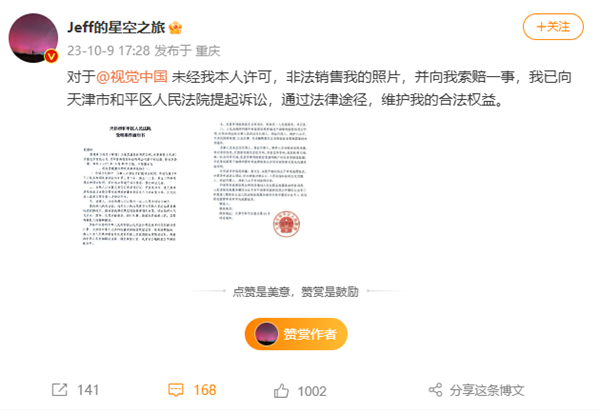
10月9日消息,今日,摄影师戴建峰Jeff的星空之旅”发文,称对于视觉中国未经本人许可,非法销售其照片,并向其索赔一事,已向天津市和平区人民法院提起诉讼。在这条微博评论区,许多网友留言刷屏表示支持”,也有网友称支持维权,视觉中国不是第一次干这种事了”。据了解,今年8月,摄影师用自己照片被视觉中国告侵权索赔8万”一事引起网络热议。站长网2023-10-09 22:49:010000一个UP主,让15年前的游戏再次伟大
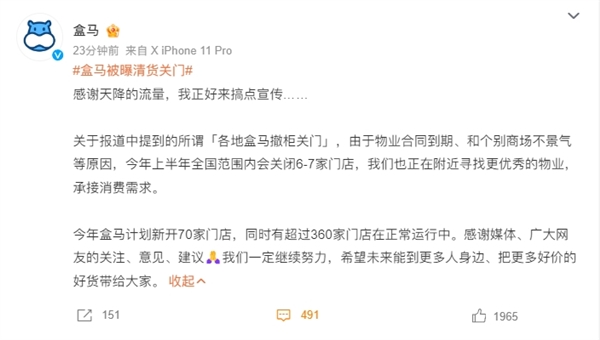
6月1日,B站UP主「潜艇伟伟迷」发了一个视频,标题是「感谢大家对植物大战僵尸杂交版的支持!」。截止到今天我们这篇内容发布,5天时间,播放量超过900万,是「潜艇伟伟迷」目前播放量最高的一条视频。目前,「潜艇伟伟迷」在B站有接近250万粉丝,这250万的粉丝当中,根据飞瓜的数据监测,近30天的涨粉数量是167万。站长网2024-06-06 21:01:230000盒马被曝清货关门 官方回应:今年计划新开70家门店
近日,网络上关于盒马撤柜关门的消息层出不穷,甚至有网友发现附近的盒马无人送货、商品种类减少等情况。有网友发帖晒图,声称盒马货架已被清空,疑似正在清货撤店,这一消息迅速引发网友热议。站长网2024-03-06 15:37:560000