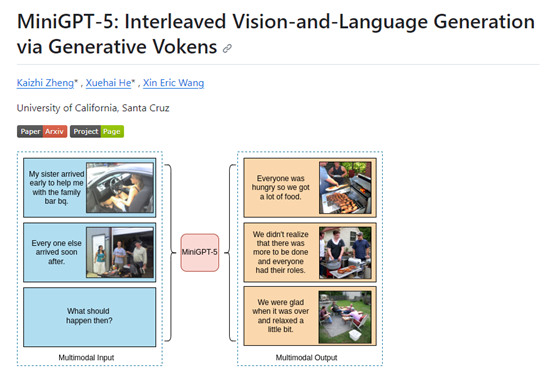
突破性技术!开源多模态模型—MiniGPT-5
多模态生成一直是OpenAI、微软、百度等科技巨头的重要研究领域,但如何实现连贯的文本和相关图像是一个棘手的难题。
为了突破技术瓶颈,加州大学圣克鲁斯分校研发了MiniGPT-5模型,并提出了全新技术概念“Generative Vokens ",成为文本特征空间和图像特征空间之间的“桥梁”,实现了普通训练数据的有效对齐,同时生成高质量的文本和图像。
为了评估MiniGPT-5的效果,研究人员在多个数据集上进行了测试,包括CC3M、VIST和MMDialog。结果显示,MiniGPT-5在多个指标上都优于多个对比基线,能够生成连贯、高质量的文本和图像。
例如,在VIST数据集上,MiniGPT-5生成的图像CLIP分数高于fine-tunedStable Diffusion2; 在人类评估中,MiniGPT-5生成的语言连贯性更好(57.18%),图像质量更高(52.06%),多模态连贯性更强(57.62%)。
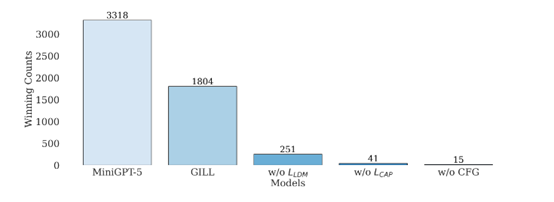
在MMDialog数据集上,MiniGPT-5的MM相关性指标达到0.67,超过基准模型Divter的0.62。这充分证明MiniGPT-5在不同数据模式下的强大适应能力。
开源地址:https://github.com/eric-ai-lab/MiniGPT-5
论文地址:https://arxiv.org/abs/2310.02239
MiniGPT-5模型主要有3大创新点:1)利用多模态编码器提取文本和图像特征,代表了一种全新的文本与图像对齐技术,效果优于直接利用大语言模型生成视觉token的方法。
2)提出了无需完整图像描述的双阶段训练策略:第一阶段,专注文本与图像的简单对齐;第二阶段,进行多模态细粒度特征学习。
3)在训练中引入了“无分类器指导”技术,可有效提升多模态生成的内容质量。主要模块架构如下。
Generative Vokens
MiniGPT-5的核心创新就是提出了“Generative Vokens”技术概念,实现了大语言模型与图像生成模型的无缝对接。
具体来说,研究人员向模型的词表中加入了8个特殊的Voken词元[IMG1]-[IMG8]。这些Voken在模型训练时作为图像的占位符使用。
在输入端,图像特征会与Voken的词向量拼接,组成序列输入。在输出端,模型会预测这些Voken的位置,对应的隐状态h_voken用于表示图像内容。
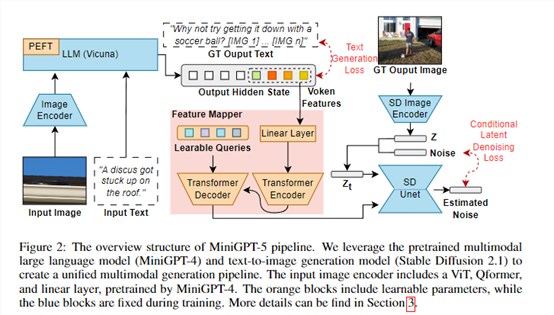
然后,h_voken通过一个特征映射模块,转换为与Stable Diffusion文本编码器输出对齐的图像条件特征ˆh_voken。
在Stable Diffusion中,ˆh_voken作为指导图像生成的条件输入。整个pipeline实现了从图像到语言模型再到图像生成的对接。
这种通过Voken实现对齐的方式,比逆向计算要直接,也比利用图像描述更为通用。简单来说,Generative Vokens就像是一座“桥梁”,使不同模型域之间信息传递更顺畅。
双阶段训练策略
考虑到文本和图像特征空间存在一定的域差异,MiniGPT-5采用了两阶段的训练策略。
第一阶段是单模态对齐阶段:只使用单个图像-文本对的数据,如CC3M。模型学习从图像标题生成对应的Voken。同时,加入辅助的图像标题损失,帮助Voken与图像内容对齐。
第二阶段是多模态学习阶段:使用包含连续多模态样本的数据,如VIST,进行微调。设置不同的训练任务,包括生成文本、生成图像和同时生成两者。增强了模型处理多模态信息的能力。
这种分阶段策略,可以缓解直接在有限数据上训练带来的问题。先进行粗粒度对齐,再微调细粒度特征,并提升了模型的表达能力和鲁棒性。
无分类器指导
为进一步提升生成文本和图像的连贯性,MiniGPT-5还采用了“无分类器指导”的技术。
其核心思想是,在图像扩散过程中,以一定概率用零特征替换条件Voken,实现无条件生成。
在推理时,将有条件和无条件的结果作为正负样本,模型可以更好地利用两者的对比关系,产生连贯的多模态输出。这种方法简单高效,不需要引入额外的分类器,通过数据对比自然指导模型学习。
文本到图像生成模型
MiniGPT-5使用了Stable Diffusion2.1和多模态模型MiniGPT-4作为文本到图像生成模型。可以根据文本描述生成高质量、高分辨率的图片。
Stable Diffusion使用Diffusion模型和U-Net作为主要组件。Diffusion模型可以将图片表示成噪声数据,然后逐步进行去噪和重构。
U-Net则利用文本特征作为条件,指导去噪过程生成对应的图片。相比GAN,Diffusion模型更稳定,生成效果也更清晰逼真。

为了准确地将生成标记与生成模型对齐,研究人员制定了一个用于维度匹配的紧凑映射模块,并结合了一些监督损失,包括文本空间损失和潜在扩散模型损失。
文本空间损失帮助模型学习标记的正确位置,而潜在扩散损失直接将标记与适当的视觉特征对齐。由于生成Vokens的特征直接由图像引导,因此,不需要图像的全面描述就能实现无描述学习。
研究人员表示,MiniGPT-5的最大贡献在于实现了文本生成和图像生成的有效集成。只需要普通的文本、图像进行预训练,就可以进行连贯的多模态生成,而无需复杂的图像描述。这为多模态任务提供了统一的高效解决方案。
本文素材来源加州大学圣克鲁斯分校论文,如有侵权请联系删除
孙燕姿的饭碗,也被AI盯上了
孙燕姿可能都没想到,自己的“代表作”会加上一个《漠河舞厅》。替孙燕姿唱歌的,是AI孙燕姿。最近,一批B站UP主用AI技术合成了孙燕姿版的《发如雪》《半岛铁盒》《红豆》,和其他港台歌手“梦幻联动”,还让孙燕姿唱起了更新的歌,《水星记》《漠河舞厅》等等,很多孙燕姿的粉丝都表示“绝对想不到孙燕姿会唱这种类型的歌。”站长网2023-05-17 14:41:440000史上最难618,谁在B站带货赚钱
流量进入存量时代,闭环电商平台站内的流量获取成本越来越高,想要在平台上做生意的商家为了维持生意增长,都在想办法通过卷内容、卷低价促成转化。一些更敏锐的商家和代理商,则在此之外开辟了另外一条战线,他们开始从站外寻找新流量。这是一个正在发生的事实,也是接下来一段时间的趋势。流量追逐者们从竞争更激烈的大平台流出,流向仍有在增长中的、仍有红利的新内容平台,其中就包括B站。0000扳回一局!Gemini-Pro多模态能力和GPT-4V不相上下
要点:Gemini-Pro在多模态能力上与GPT-4V不相上下,尤其在多模态专有基准MME上表现出1933.4的高分,超过GPT-4V。在37个视觉理解任务中,Gemini-Pro在文本翻译、颜色/地标/人物识别、OCR等任务中表现突出,而GPT-4V在名人识别任务上得分为0。站长网2023-12-22 15:03:390000谷歌与Hugging Face携手,共推开源模型助力AI发展
**划重点:**1.🤝Google与HuggingFace宣布战略合作,整合开放AI和机器学习开发,旨在通过将HuggingFace平台与GoogleCloud基础设施集成,包括VertexAI,使生成式AI更易于开发者使用。站长网2024-01-29 15:22:400000小米一季度出货量大涨33%:稳坐全球第三 无限逼近苹果
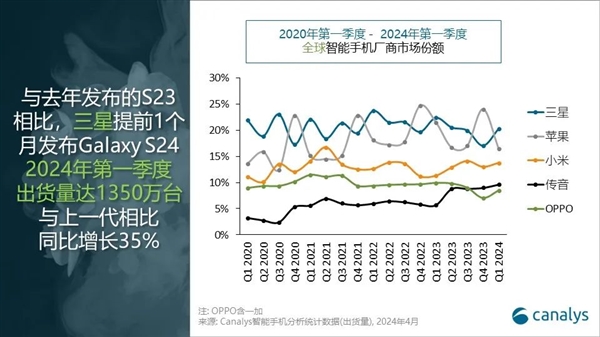
快科技4月30日消息,分析机构Canalys今天发布了2024年第一季度全球智能手机市场数据。该季度全球智能手机市场同比增长10%,达到2.962亿部,市场表现高于预期,这意味着手机行业的最低谷已经度过。三星在A系列和新款高端旗舰GalaxyS24系列的推动下实现遥遥领先,出货量达6000万部,出货量第一。苹果在华为等挑战下,出货量下滑16%,降至4870万部,位居第二,市场份额16%。站长网2024-05-01 15:06:490000