Google发布PaLI-3视觉语言模型,性能相当于体积大10倍的模型
📌划重点:
Google Research和Google DeepMind发布了PaLI-3,这是一款仅有50亿参数的视觉语言模型(VLM)。
尽管相对较小,PaLI-3在多模态测试中超越了体积大10倍的模型,可以回答关于图像的问题、描述视频、识别对象和读取图像上的文本。
尽管规模较小,PaLI-3的性能表现卓越,这归功于对SigLIP方法的对比预训练视觉转换器的应用。小型模型更适合培训和部署,更环保,并允许更快的模型设计研究周期。
Google Research和Google DeepMind日前发布了名为PaLI-3的新一代视觉语言模型(VLM),尽管仅拥有50亿参数,但其性能令人瞩目。与体积大10倍的竞争对手相比,PaLI-3在多模态测试中表现出色,能够回答关于图像的问题、描述视频、识别对象和读取图像上的文本。
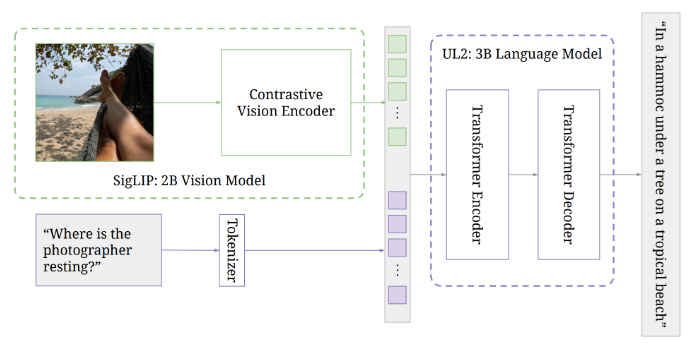
通常情况下,VLM由预训练的图像模型和语言模型组成,后者已经学会将文本与图像相关联。PaLI-3的架构遵循了其前身的先例,包括一个将图像编码为标记的视觉转换器,这些标记连同文本输入一起传递给一个编码器-解码器转换器,产生文本输出。
Google此前已经展示,高度扩展的视觉转换器并不一定会对仅涉及图像的任务(如ImageNet)产生更好的结果,但对于回答有关图像的问题等多模态任务,它可以取得显著的性能提升。随着PaLI-X的推出,Google将模型规模扩大到了550亿参数。
与PaLI-X相比,PaLI-3采用了一种新的训练方法,使用了对比预训练的视觉转换器(SigLIP),类似于CLIP。该视觉转换器仅拥有20亿参数,与语言模型一起,PaLI-3仅有50亿参数。
这种小型模型更适合培训和部署,对环境更友好,并允许更快的模型设计研究周期。令人印象深刻的是,尽管规模相对较小,PaLI-3在超过10个图像转语音测试中与今天的最佳VLM表现相媲美,而且在没有经过视频数据训练的情况下,在需要回答关于视频的问题的测试中也取得了新的最佳成绩。
虽然小型模型具有巨大的潜力,但模型领域的趋势似乎将朝着更大型模型的方向发展。不过,正是PaLI-3在其体积相对较小的情况下表现出色,彰显了SigLIP方法在未经结构化的多模态数据上进行视觉转换器训练的潜力。考虑到这种未经结构化的多模态数据的可用性,Google可能很快会推出更大版本的PaLI-3。
该研究团队表示,PaLI-3的性能表现,尽管仅有50亿参数,重新激发了对复杂VLM核心组成部分的研究兴趣,并有望推动新一代大规模VLM的发展。
项目网址:https://github.com/kyegomez/PALI3
超大福利!Runway启动创意合作伙伴计划:为精选用户提供百万积分奖励
文章概要:1.创意合作伙伴计划为选定用户提供无限计划和100万积分。2.计划还提供新功能和AI模型的优先访问权限。3.此举类似YouTube的创作者伙伴计划,有助培育生态系统。AI初创公司Runway最近启动了创意合作伙伴计划,向选定的一组用户提供访问新功能和AI模型的优先权限、免费的无限计划和100万积分。这一计划为Runway的选定用户提供了巨大的福利。站长网2023-08-30 09:50:070000微软将以21亿美元投资扩大在西班牙的人工智能基础设施
**划重点:**1.💼微软计划在未来两年内投资21亿美元,扩大其在西班牙的人工智能和云基础设施。2.🌐此举紧随微软宣布将在未来两年内在德国投资32亿欧元(34.5亿美元)用于人工智能项目。3.🤔对于西班牙投资的详细信息,微软尚未回应。站长网2024-02-20 11:14:250000推特在苹果商店更名为X 或为首家单字符批准
根据报道,Twitter应用在苹果AppStore上已经更名为X,这可能是因为该公司获得了苹果的特批。产品设计师NickSheriff此前在Twitter上表示,在iOS上苹果不允许任何应用使用单个字符作为命名。获得苹果的特批也说明了Twitter在品牌知名度和用户影响力方面具有很强的优势。此外,改名也是为了更好地满足用户需求和提升品牌形象。站长网2023-07-31 14:28:520001研究发现,AI聊天机器人可以改善在线政治辩论
在实地实验中,研究人员使用语言模型的实时措辞辅助来提高美国枪支管制聊天中的讨论质量,最终表明即聊天机器人可以对辩论文化产生积极影响。研究人员总共招募了1,574名对美国枪支管制持不同看法的人。与会者在在线聊天室中讨论了这个问题。大型语言模型(GPT-3)读取对话并在发送消息之前建议替代措辞。该建议旨在使消息更加令人放心、有效或礼貌。注:图片由midjourney生成站长网2023-05-09 11:22:560000云闪付没大面积推广原因揭秘
云闪付作为一款智能支付产品,自2017年推出以来一直备受关注。相较于其他支付方式,它有着更加便捷快速的使用体验和更加安全可靠的支付方式。但是,尽管云闪付在一些地区和领域内得到了广泛的应用,但是在大面积推广方面仍然存在一些困难。站长网2023-05-24 06:17:400000