在视觉提示中加入「标记」,微软等让GPT-4V看的更准、分的更细
最近一段时间,我们见证了大型语言模型(LLM)的显著进步。特别是,生成式预训练 Transformer 或 GPT 的发布引领了业界和学术界的多项突破。自 GPT-4发布以来,大型多模态模型 (LMM) 引起了研究界越来越多的兴趣,许多工作致力于构建多模态 GPT-4。
近日,GPT-4V (ision) 由于出色的多模态感知和推理能力得到了大家格外的关注。然而,尽管 GPT-4V 具有前所未有的视觉语言理解能力,但其细粒度 visual grounding(输入是图片和对应的物体描述,输出是描述物体的 box)能力相对较弱,或者尚未发挥出来。
举例来说,当用户询问下图中「放置在右边笔记本电脑的左边是什么物体?」GPT-4V 给出了马克杯这个错误的答案。当用户接着询问,「想找一个靠窗的座位,我可以坐在哪里?」GPT-4V 同样回答不正确。

在意识到上述问题后,来自微软、香港科技大学等机构的研究者提出了一种新的视觉 prompt 方法 Set-of-Mark(SoM),来解决 GPT-4V 在细粒度视觉任务上的问题。

论文地址:https://arxiv.org/pdf/2310.11441.pdf
论文主页:https://som-gpt4v.github.io/
如图1(右)所示,SoM 采用交互式分割模型(例如 SAM)将图像划分为不同粒度级别的区域,并在这些区域上添加一组标记(mark),例如字母数字、掩码(mask)、框(box)。使用添加标记的图像作为输入,以解决上述问题。
我们先来看下效果,左为 GPT-4V,右为 GPT-4V SoM,很明显后者分类更细致、准确。

下图示例依然如此,GPT-4V SoM 效果更明显。

此外,对于这项研究,有人问道:「SoM 是手动(人工输入)还是自动的?」

论文一作 Jianwei Yang 表示,SoM 是自动或半自动的。他们编译了很多自己构建自己的分割工具,比如 SEEM、Semantic-SAM 和 SAM,用来帮助用户自动为图像分割区域。同时用户也可以自己选择区域。

用于视觉的 SoM prompt
使用 SoM prompt GPT-4V 的独特优点是它可以产生文本之外的输出。由于每个标记都与掩码表征的图像区域特定关联,因此可以追溯文本输出中任何提到的标记的掩码。

生成成对文本和掩码的能力使 SoM 能够 prompt GPT-4V 来生成视觉关联的文本,更重要的是支持各种细粒度视觉任务,这对普通的 GPT-4V 模型来说是一个挑战。
通过简单的 prompt 工程,SoM 可以让 GPT-4V 广泛地用于多种视觉任务,例如:
开放词汇图像分割:该研究要求 GPT-4V 详尽地给出所有标记区域的类别以及从预定池中选择的类别。
参考分割:给定一个参考表达式,GPT-4V 的任务是从图像分区工具箱生成的候选区域中选择最匹配的区域。
短语关联(Phrase Grounding):与参考分割略有不同,短语关联使用由多个名词短语组成的完整句子。该研究要求 GPT-4V 为所有标记的短语分配相应的区域。
视频对象分割:以两个图像作为输入。第一个图像是查询图像,其中包含第二个图像中需要识别的一些对象。鉴于 GPT-4V 支持多个图像作为输入,因此 SoM 也可以应用于视频中跨帧的关联视觉对象。
实验及结果
研究者使用「分而治之」(divide-and-conquer)的策略来运行实验和评估。对于每个实例,他们使用新的聊天窗口,这样一来,评估期间就不会出现上下文泄露了。
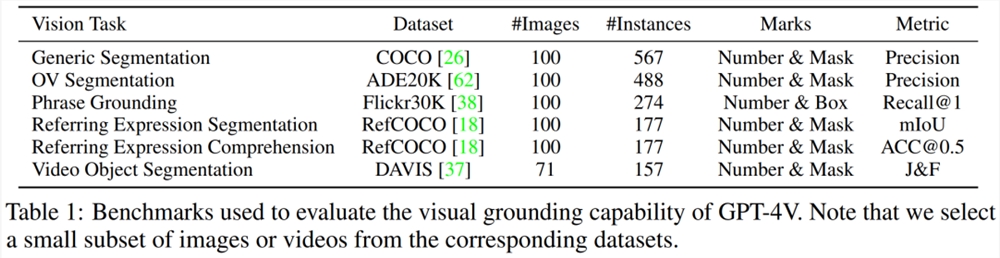
具体来讲,研究者从每个数据集中选择了小规模的验证数据子集。对于数据集中的每个图像,他们在使用图像分割工具箱提取的区域上覆盖了一组标记。同时基于具体的任务,研究者利用不同的分割工具来提出区域。
下表1列出了每个任务的设置细节。
研究者将其方法与以下模型进行比较:
预测坐标的 GPT-4V 基线模型
SOTA 专用模型
开源 LMM
定量结果
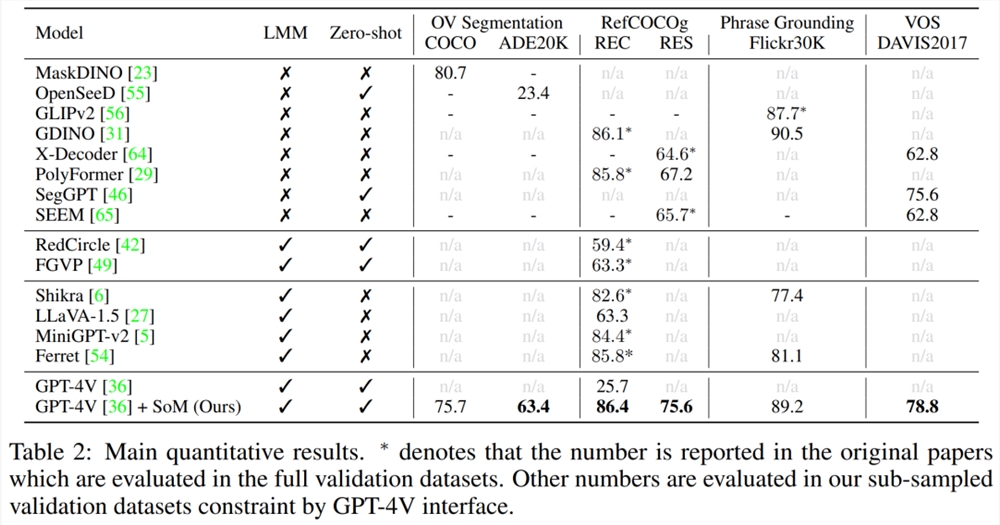
详细的实验结果如下表2所示。
首先是图像分割任务。研究者将 GPT-4V SoM 与 COCO Panoptic 分割数据集上的强大分割模型 MaskDINO、ADE20K Panoptic 分割数据集上的模型 OpenSeeD 进行了比较。
结果显示,GPT-4V SoM 的零样本性能接近微调后的 MaskDINO,并大幅优于 OpenSeeD。GPT-4V 在 COCO 和 ADE20K 上的相似性能表现出其对广泛视觉和语义域任务的强大泛化能力。
然后是参考(referrring)任务,研究者评估了 RefCOCOg 数据集上的模型 RES 和 REC。他们使用 MaskDINO 来提出掩码,并在图像上覆盖上掩码和数字。同时使用 mIoU 作为评估指标,并与 SOTA 专用模型 PolyFormer 和 SEEM 进行比较。
结果显示,GPT-4V SoM 击败了 Grounding DINO、Polyformer 等专用模型以及 Shikra、LLaVA-1.5、MiniGPT-v2和 Ferret 等最近的开源 LMM。
接着是 Flickr30K 上的短语关联任务,研究者使用 Grounding DINO 为每个图像生成框建议。GPT-4V SoM 实现了比 GLIPv2和 Grounding DINO 更强的零样本性能。
最后研究者在 DAVIS2017数据集上评估了视频分割任务。GPT-4V SoM 实现了优于其他专用视觉模型的最佳追踪性能(78.8J&F)。
消融研究
研究者探讨了标记类型如何影响 Flickr30k 数据集上短语关联任务的最终性能,并比较了两种类型的标记。第一种是数字和掩码,第二种是数字、掩码和框。
结果如下表3所示,添加额外的框可以显著提升性能。

此外研究者探究了当生成带有真值注释的标记时,GPT-4V 如何表现。他们选择在 RefCOCOg 验证集中用真值掩码替换预测到的分割掩码。这意味着 GPT-4V 只需要从注释短语区域选择一个即可。如预期一样,参考分割的性能可以得到进一步提升,尤其是当分割模型有一些缺失的区域。
结果如下表4所示,在 SoM 中使用真值掩码可以将 RefCOCOg 上的性能提升14.5%(mIoU)。

更多技术细节和实验结果参阅原论文。
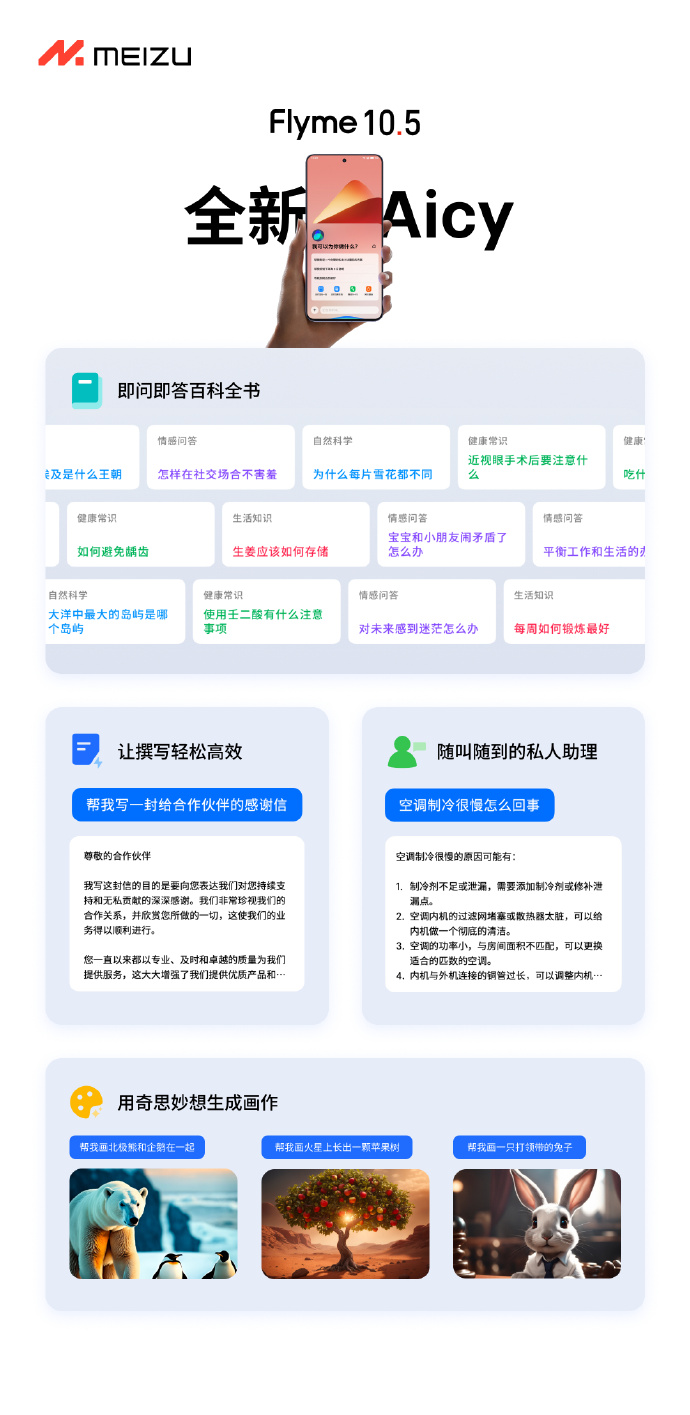
Flyme AI大模型加持!魅族Flyme 10.5引入全新智能助手Aicy
魅族宣布,Flyme10.5将引入全新的智能助手Aicy,通过FlymeAI大模型的加持,Aicy能够发挥出强大的能力。首先,Aicy能够作为即问即答的百科全书,回答包括自然科学、生活知识、健康常识、情感问答等各类问题。其次,Aicy还能帮助用户撰写各种文本,包括微博动态、感谢信、年会发言稿等。站长网2023-11-30 15:40:470000超真实的虚拟试衣软件IDM-VTON 连衣服的褶子都那么真实
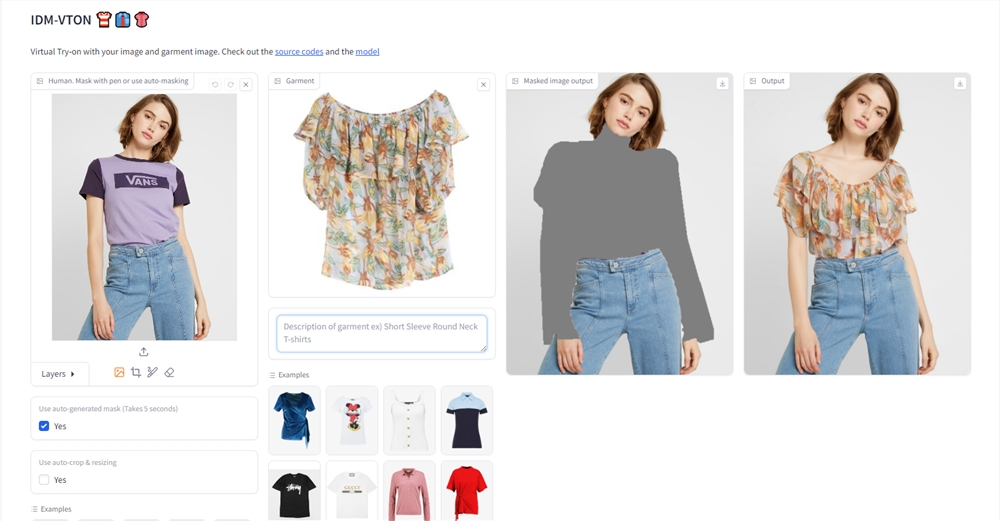
近日,一项名为IDM-VTON的虚拟试衣技术引起了广泛关注。这项技术能够生成高度真实的虚拟试衣图像,其细节处理之精细,令人赞叹不已。IDM-VTON技术的核心在于其对服装细节的精准捕捉。无论是纹理、图案还是缝线,这些细微之处都能在试衣图像中得到准确的再现。这种对细节的高度还原,使得用户在试衣时能够更加真实地感受到衣物的质感和设计。技术特点:站长网2024-04-26 04:10:480001苹果发布iOS 17 语音助手不用再说“嘿 Siri”了
今日凌晨,苹果发布了iOS17预览版,为电话app、FaceTime通话app和信息app的通信体验带来重大提升,iOS17还带来两项全新体验:Journalapp以及StandBy功能。支持设备方面,iOS17不再支持iPhone8、iPhone8Plus和iPhoneX三款机型。站长网2023-06-06 16:24:520000余额宝宣布上线11年:累计为用户赚4499亿元
今日,余额宝迎来了其成立的第11个年头。据官方数据显示,在过去的十一年里,余额宝已为用户累计赚取了高达4499亿元的收益。截至目前,余额宝平台已与41家基金公司的45只货币基金建立了紧密的合作关系,为投资者提供了多样化的选择。站长网2024-06-21 21:30:380000