斯坦福博士推加速推理新方法Flash-Decoding 长上下文LLM推理速度提8倍
要点:
1. FlashAttention团队推出了一种新的方法,Flash-Decoding,用于加速大型Transformer架构的推理,最高可提速8倍,特别适用于长上下文LLM模型。
2. Flash-Decoding的优点在于使用并行操作加载Key和Value缓存,然后重新缩放和合并结果,以显著提高推理速度。
3. 这个方法在CodeLLaMa-34b上进行了基准测试,结果显示Flash-Decoding可以将长序列解码速度提高8倍,同时具有更好的扩展性。
FlashAttention团队最近推出了一项名为Flash-Decoding的新方法,旨在加速大型Transformer架构的推理过程,特别是在处理长上下文LLM模型时。这项方法已经通过了64k长度的CodeLlama-34B的验证,而且得到了PyTorch官方的认可。
Flash-Decoding的核心思想是通过并行操作来加载Key和Value缓存,然后重新缩放并合并结果,从而实现大幅的推理速度提升。这个方法克服了在处理大型模型时注意力计算带来的性能瓶颈。
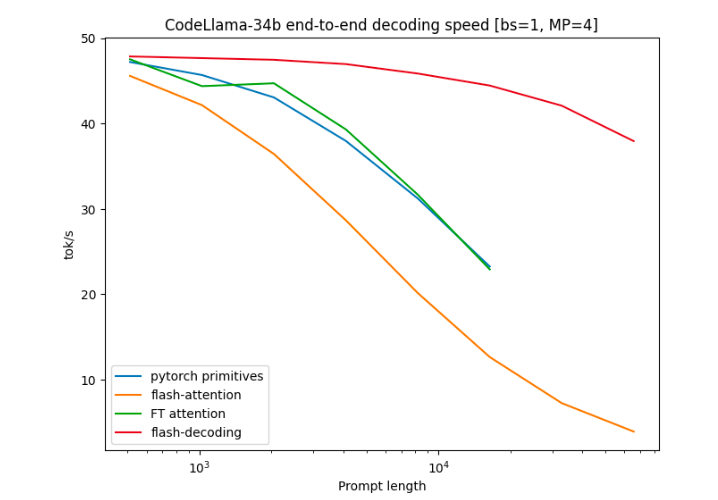
在基准测试中,作者将Flash-Decoding与其他注意力计算方法进行了比较,包括PyTorch原语运行的注意力、FlashAttention v2以及FasterTransformer的注意力内核。结果显示,Flash-Decoding可以将长序列解码速度提高8倍,并且在处理不同序列长度和批处理大小时表现出更好的扩展性。
这一方法的出现为大型Transformer模型的推理过程提供了更高效的解决方案,特别是在处理长上下文模型时,将大幅提高推理速度,有望在未来的大型自然语言处理任务中发挥重要作用。Flash-Decoding的实际使用方法也相对简单,可以根据问题的大小自动选择使用Flash-Decoding或FlashAttention方法。
作者团队中的Tri Dao是FlashAttention的主要作者,他已经加入大模型创业公司Together AI,并将担任普林斯顿大学的助理教授。这个新方法的推出为深度学习领域带来了更多的创新和性能提升。
参考资料:https://princeton-nlp.github.io/flash-decoding/
微信加大“自媒体”造谣治理力度:限制增粉、阶梯封号
快科技1月3日消息,微信官方发布《关于持续治理自媒体”违规问题的公告》。公告称,微信加大自媒体”造谣传谣、假冒仿冒等问题的治理力度,进一步引导自媒体”创作者规范打标,切实履行平台主体责任,持续落实清朗从严整治自媒体乱象”专项行动、《关于加强自媒体”管理的通知》等有关要求,从严处置相关违规账号和内容。1、从严打击造谣传谣,搬运传播谣言的自媒体”0000汉得信息:汉得AIGC中台即将正式发布
今日,汉得信息宣布,汉得AIGC中台即将正式发布,以帮助企业更便捷地应用AIGC知识问答能力。借助汉得AIGC中台的知识问答组件,企业可以快速搭建各个领域的知识库,无论是门店销售、售后客服、设备维护或是财务共享,均可以快速利用AIGC带来效率的显著提升。站长网2023-06-30 19:36:080002高德地图功能升级:无灯路口有来车能提醒了
快科技6月8日消息,高德地图今日宣布带来独家功能升级,车道级安全预警功能覆盖了10大安全风险较高的行车场景。升级点如下:前方有车辆急刹:当道路上有车辆出现急刹行为的时候,可在第一时间通知其后方用户注意,预防因急刹产生的追尾事故,提升行车安全。无灯路口有来车:实时监测路口盲区来车情况,精准预知货车、快速车的会车风险。站长网2024-06-11 17:13:120000美国迫使沙特基金退出Altman支持的人工智能芯片初创公司
##划重点:🧠**人工智能芯片初创公司退出:**美国政府迫使沙特阿美支持的风险投资公司在硅谷的人工智能芯片初创公司RainNeuromorphics出售其股份,该公司由OpenAI联合创始人SamAltman支持。🌐**国家安全关切:**Altman支持的RainNeuromorphics筹集了2022年的2500万美元,站长网2023-12-01 14:41:0000001米糖葫芦硬控年轻人,半个月爆卖超15万单
“冰糖葫芦甜又甜,红红山楂圆又圆”,你听过这首童谣吗?你吃过糖葫芦吗?如今,插在草垛上的糖葫芦变成了大街小巷的拍照景观。许多年轻人,举着“1米糖葫芦”,分享着自己甜蜜的心情。一米糖葫芦最早在东北街头被发现,现在已经扩展到全国多个城市和景点,成为网红小吃。哈尔滨的中央大街、北京的南锣鼓巷、西安的钟鼓楼、济南的芙蓉街,以及上海、浙江等地也都能看到它的身影。0000












