T2I扩散模型PIXART-α:图像生成质量媲美Stable Diffusion
划重点:
新时代的逼真图像合成:文本到图像(T2I)生成模型DALLE2、Imagen和Stable Diffusion,对后续应用产生深远影响。
降低成本的高质量图像生成:研究人员提出PIXART-α,大幅降低了训练成本,同时保持了与最新图像生成器相媲美的图像质量。
改进文本到图像生成:通过创新方法,包括训练策略和数据集改进,提高了T2I模型的效率和质量。
最近,文本到图像(T2I)生成模型如DALLE2、Imagen和Stable Diffusion的发展,开启了逼真图像合成的新时代。这不仅对图片编辑、视频制作、3D素材创建等领域产生了深远影响,还为研究社区和企业提供了许多下游应用的机会。

然而,这些复杂的模型需要巨大的计算资源来进行训练。例如,训练SD v1.5需要6,000块A100GPU,成本约为32万美元。而更大的模型RAPHAEL,甚至需要60,000块A100GPU,成本高达308万美元。此外,训练会产生大量的二氧化碳排放,给环境造成了压力,例如,RAPHAEL的训练会产生35吨的二氧化碳排放,相当于一个人七年的排放量。
这种高昂的价格限制了研究社区和企业获得这些模型,严重阻碍了人工智能生成内容(AIGC)领域的发展。关键问题是,是否可以以更少的资源开发高质量的图像生成模型?
来自华为诺亚方舟实验室、大连理工大学、香港大学和香港科技大学的研究人员提出了PIXART-α,它显著降低了训练成本,同时保持了与最新图像生成器相匹敌的图像质量。他们提出了三个主要的设计思路:
首先,他们通过分解训练计划,将文本到图像生成问题划分为三个简单的子任务:学习自然图像像素的分布、学习文本图像对齐以及提高图像的美观度。通过使用低成本的类别条件模型初始化T2I模型,大幅降低了第一个子任务的学习成本。其次,他们提出了一个训练范例,包括在信息密度高的文本图像对数据上进行预训练,然后在更高审美质量的数据上进行微调,以提高训练效果。他们还使用交叉注意力模块来注入文本条件,并简化了计算密集的类别条件分支,从而提高了效率。
此外,他们提出了一种重新参数化方法,可以让修改后的文本到图像模型直接导入原始类别条件模型的参数。这样一来,他们可以利用ImageNet关于自然图片分布的过去知识,为T2I Transformer提供合理的初始化,加速训练过程。
在高质量信息方面,他们的研究揭示了现有的文本-图像对数据集存在显著缺陷,例如LAION。文本描述经常受到严重的长尾效应影响(即很多名词出现频率极低),而且缺乏信息内容(通常只描述图像中的一部分物体)。这些缺陷极大地降低了T2I模型训练的效果,需要数百万次迭代才能获得可靠的文本图像对齐。他们建议使用最先进的视觉-语言模型进行自动标注,以在SAM上生成说明,从而克服这些问题。
SAM数据集具有大量多样化的对象,这使其成为生成信息密度高的文本-图像对的理想来源,更适合文本-图像对齐学习。他们的聪明方法使其模型的训练非常高效,仅需675块A100GPU天和26,000美元。与Imagen相比,他们的方法使用更少的训练数据量(0.2% vs. Imagen)和更短的训练时间(2% vs. RAPHAEL)。他们的训练费用约为RAPHAEL的1%,为他们节省了约300万美元。
关于生成质量,他们的用户研究试验显示,PIXART-α提供了比当前SOTA T2I模型、Stable Diffusion等更好的图像质量和语义对齐,此外,它在T2I-CompBench上的性能显示出在语义控制方面具有优势。
他们预计,他们有效训练T2I模型的努力将为AIGC社区提供有用的见解,并帮助更多的独立学术界或公司以更实惠的价格生成高质量的T2I模型。
总之,PIXART-α具有以下特色和功能:
高质量图像生成:PIXART-α基于Transformer技术,能够生成高质量、艺术性强、高细节、广角镜头的图像,包括明亮的场景、鸟瞰图、古城、幻想、华丽的光线、镜面反射等。
低培训成本:与其他先进的文本到图像模型相比,PIXART-α的培训成本明显降低,仅需相对较少的训练资源,从而显著降低了培训过程中的时间和经济成本。
高分辨率图像合成:PIXART-α支持高分辨率图像的合成,可以生成高达1024px分辨率的图像,这有助于满足商业应用的需求。
训练效率:该模型提出了一种训练策略分解,通过优化不同的训练步骤来提高训练效率,包括像素依赖性、文本图像对齐和图像美学质量的优化。
CO2排放减少:PIXART-α的低培训成本也导致了较低的CO2排放,对环境友好,有助于减少碳排放。
支持文本-图像对齐:该模型强调了文本-图像对之间概念密度的重要性,并利用大型视觉语言模型自动标记密集的伪标题以提高文本-图像对齐的质量。
控制功能:PIXART-α还提供了控制功能,允许用户生成定制图像,精确修改物体颜色等,以满足特定需求。
PIXART-α论文网址:https://arxiv.org/abs/2310.00426
PIXART-α项目网址:https://pixart-alpha.github.io/
谷歌宣布人工智能驱动的隐私平台 Checks:简化应用隐私合规并节省时间
作为Area120孵化器计划的一部分,GoogleChecks于2022年2月推出,旨在帮助日益关注隐私权和数据收集的应用程序开发人员。它通过让开发人员访问易于使用的工具来帮助他们简化隐私合规并节省时间。今天,谷歌宣布他们已经将Checks完全集成到他们的产品线中。图片截自GoogleChecks站长网2023-05-04 11:51:540000爱情教主小红书:现实恋爱稀碎,网上劝人分手
想分手,就上小红书男朋友七夕节没有给我准备礼物,怎么办?——“分!”、“不要恋爱脑,男人多得是”、“这段恋爱,正在消耗你”、“他不爱你”,“恋爱时这样,结婚后更可怕”,相似的对话不断在小红书情感帖子的评论区上演。站长网2023-08-22 22:30:530000电子是粒子也是波?本质上来讲万物皆波,包括你和我
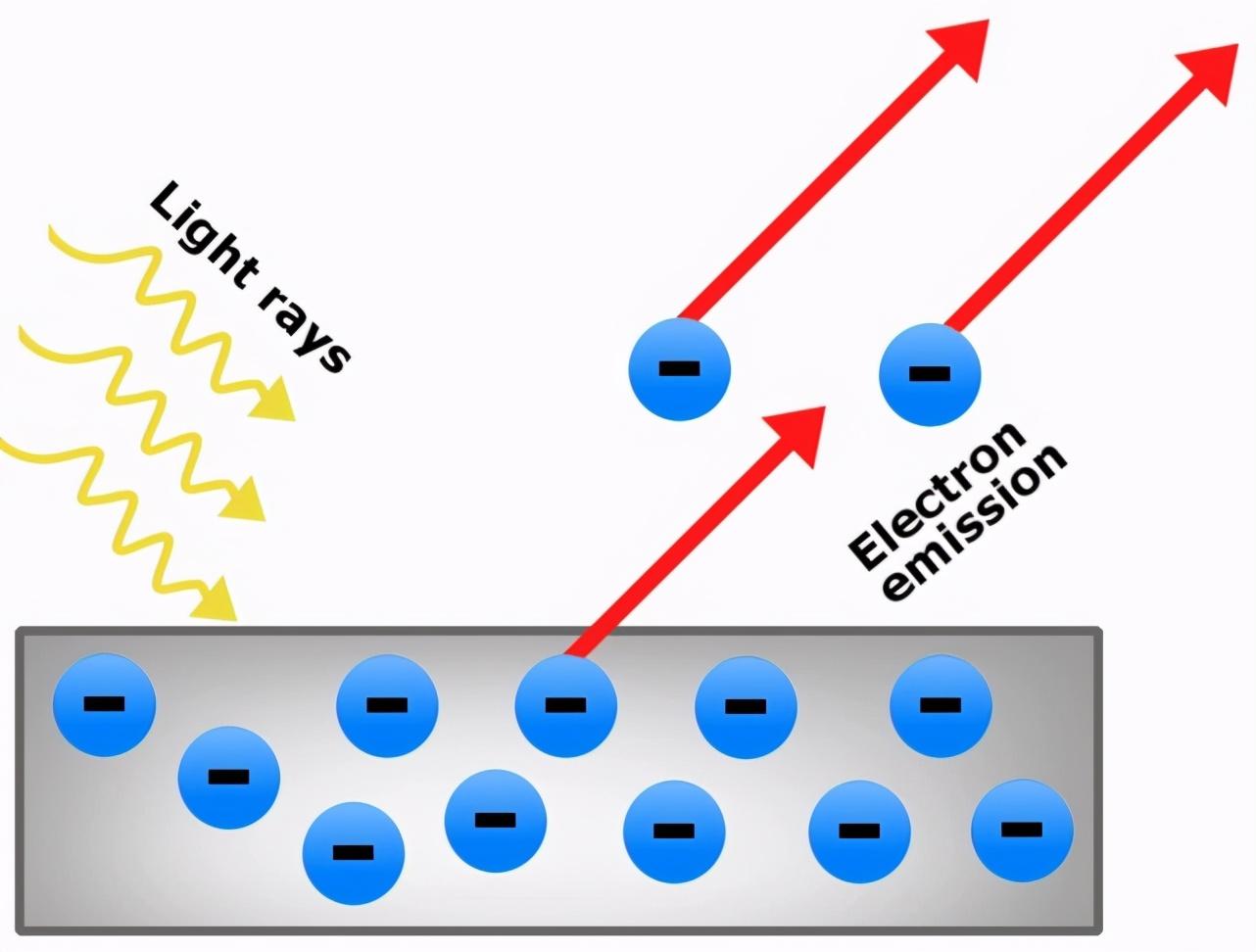
说到波粒二象性,很多人首先会想到的或许就是光。光具有波粒二象性,光是电磁波,但也具有粒子特性,爱因斯坦的光电效应已经验证了这点,而爱因斯坦也因为发现了光电效应获得了诺贝尔物理学奖。何为“光电效应”?简单讲,如果光仅仅是波,它就不可能把电子从金属表面撞击出来,只有光像离散的光子包,才可能从金属表面把电子撞出来,而光子包其实就是光的粒子性。站长网2023-05-24 23:23:140003出海泛娱乐应用靠AI玩法月入百万美金,背后技术竟是来自同一家中国大模型企业
近期,一场社交应用下架风波引发出海应用企业圈层广泛关注,如何让应用工具在更合法合规的模式下运行,并且要保证应用玩法不断更新,为用户带来新鲜的体验感,这个课题成为出海人关注的重点。在对大量泛娱乐赛道产品进行观察过程中我们发现,AI技术和新玩法的融入,成为当下泛互出海产品最佳的选择。0000PDF.ai:免费且无需注册的聊天式 PDF 助手
PDF.ai是一个完全免费、无需注册的在线工具,所有工具都在浏览器中运行,以确保用户的隐私。这个工具可以满足几乎所有与PDF相关的需求,包括合并PDF、拆分PDF、将PDF转换为PNG、将PDF转换为JPEG、将PNG转换为PDF、将JPEG转换为PDF、将PDF转换为HTML、OCRPDF、压缩PDF和旋转PDF。站长网2023-08-09 11:29:570001