谷歌最新技术:通过搜索引擎,极大增强ChatGPT等模型的准确率
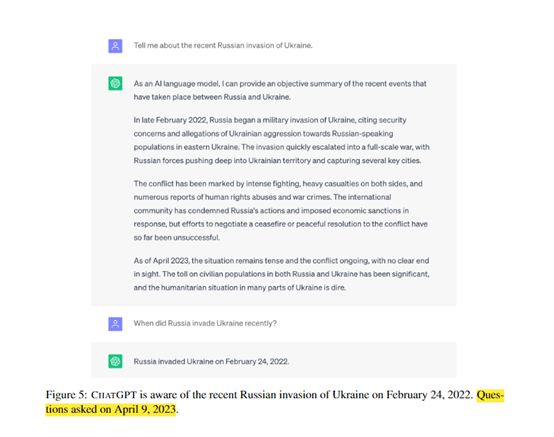
由于Transformer的出现,使得ChatGPT等大语言模型在处理自然语言任务上的能力得到了大幅度提升。但生成的内容却包含大量错误或过时的信息,同时缺乏事实性评估体系,来验证内容的真伪。
为了全面评估大语言模型对世界变化的适应能力和内容的真实性,谷歌AI研究团队发布了一篇名为《通过搜索引擎知识增强大语言模型的准确性》的论文。提出了一种FRESHPROMPT的方法,可通过从搜索引擎获取实时信息,来提升ChatGPT、Bard等大型语言模型的准确性。
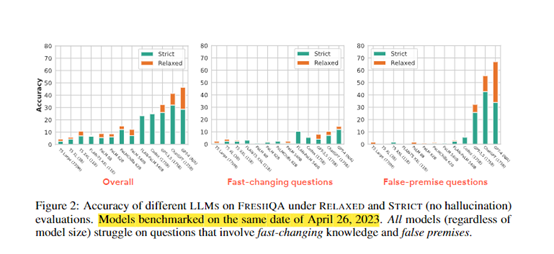
研究人员构建了一个新的问答基准测试集FRESHQA,其中包含600个各类真实问题,答案变化频率分为“永不改变”“变化缓慢”“变化频繁”和“错误前提”四大类别。
同时,还设计了严格模式和宽松模式两种评估方法,前者要求回答中的所有信息必须准确最新,后者仅评估主要回答的正确性。
实验结果显示,FRESHPROMPT明显提升了大语言模型在FRESHQA上的准确率。例如,GPT-4在FRESHPROMPT的严格模式帮助下,比原始GPT-4提升了47%准确率。
此外,相比于直接扩大模型的参数,这种融合搜索引擎的方法更加灵活,可以为已有模型提供动态的外部知识源。实验结果也证明FRESHPROMPT可以明显提升大语言模型在需要实时知识的问题上的准确率。
论文地址:https://arxiv.org/abs/2310.03214
开源地址:https://github.com/fresh大语言模型s/freshqa (正在筹备中,将很快开源)
从谷歌论文内容来看,FRESHPROMPT的方法主要由5大模块组成。
构建FRESHQA基准测试集
为了全面评估大语言模型对变化世界的适应能力,研究人员首先构建了FRESHQA基准测试集,其包含600个真实的开放域问题,根据答案变化的频率可以分为“永不改变”“变化缓慢”“变化频繁”和“错误前提”四大类别。
1)永不改变:答案基本不会改变的问题。
2)变化缓慢:答案每几年改变一次的问题。
3)变化频繁:答案每年或更短时间内就可能改变的问题。
4)错误前提:包含不正确前提的问题。

这些问题涵盖各种话题,具有不同的难度级别。FRESHQA的关键特点是答案可能会随时间变化,所以模型需要具备对世界变化的敏感认知能力。
严格模式与宽松模式评估
研究人员提出了两个评估模式:严格模式要求回答中所有信息必须准确最新,宽松模式仅评估主要答案的正确性。
这提供了更全面和细致的方式来测量语言模型的事实性。
基于FRESHQA评估不同大语言模型
在FRESHQA上,研究人员比较了涵盖不同参数的大语言模型,包括GPT-3、GPT-4、ChatGPT等。评估采用严格模式(要求无错误)和宽松模式(仅评估主要答案)。
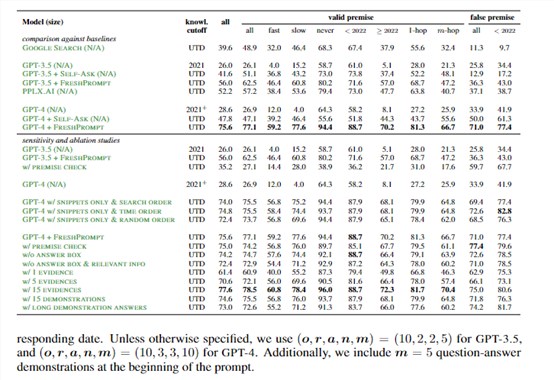
结果发现,所有模型在需要实时知识的问题上表现较差,尤其是频繁变化和错误前提的问题。这说明当前大语言模型对变化世界的适应力存在局限。
从搜索引擎中检索相关信息
为提高大语言模型的事实性,FRESHPROMPT的核心思路是从搜索引擎中检索问题相关的实时信息。
具体而言,给定一个问题,FRESHPROMPT会将其作为关键词查询谷歌搜索引擎,获取包含答案框、网页结果、“其他用户也问”等多种类型的搜索结果。
通过稀疏训练整合检索信息
FRESHPROMPT使用稀疏训练(few-shot learning)的方式,将检索到的各个证据以统一格式整合到大语言模型的输入提示中,同时提供几个示范,说明如何综合这些证据得出正确回答。
这样可以教会大语言模型去理解这个任务,并整合不同来源的信息来推理出最新准确的答案。
谷歌表示,FRESHPROMPT对提升大语言模型的动态适应能力具有重要意义,这也是大语言模型未来技术研究的一个重要方向。

本文素材来源谷歌论文
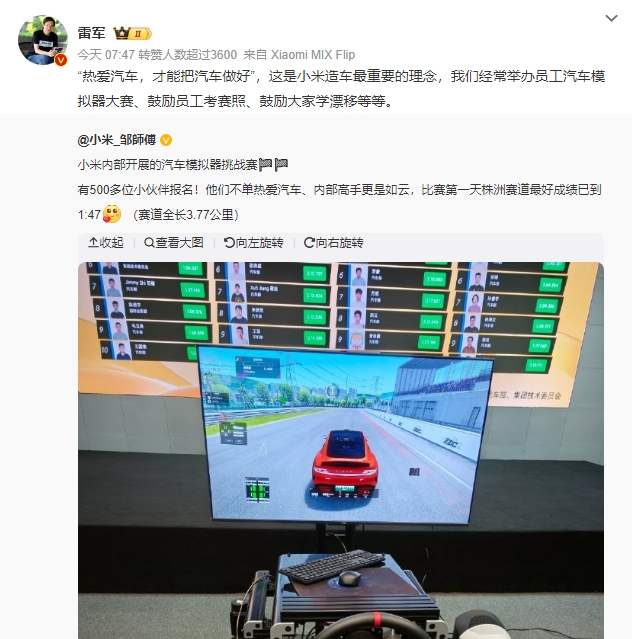
雷军:热爱才能把汽车做好 小米内部鼓励员工考赛照、学漂移
站长之家(ChinaZ.com)10月24日消息:小米创始人雷军近日分享了小米能够在汽车行业迅速崭露头角的秘诀。他在多个社交平台上发文表示,每当他想到在赛道上驰骋的场景,都会感到热血沸腾。雷军透露,他坚持造车的初衷是出于对汽车的热爱和敢想敢做的决心。站长网2024-10-24 11:10:560000ChatGPT 的所有者 OpenAI 正在探索制造自己的人工智能芯片
根据知情人士透露,ChatGPT背后的OpenAI公司,正在考虑制造自己的人工智能芯片,并已评估潜在的收购目标。根据最近的内部讨论,公司尚未决定是否继续前进。然而,根据知情人士透露,自去年以来,它已经讨论了解决OpenAI依赖的昂贵人工智能芯片短缺的各种选项。这些选项包括制造自己的人工智能芯片,更密切地与其他芯片制造商合作,包括英伟达,并将供应商多样化,超越英伟达之外。站长网2023-10-07 09:02:340000AI日报:Claude推Artifacts分享、重新混合功能;Magnific发布PS插件;Ollama0.2版本发布
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、独立开发者狂喜!Claude推Artifacts分享功能可在别人基础上修改站长网2024-07-11 08:56:440000解剖Sora:37页论文逆向工程推测技术细节,微软参与,华人团队出品
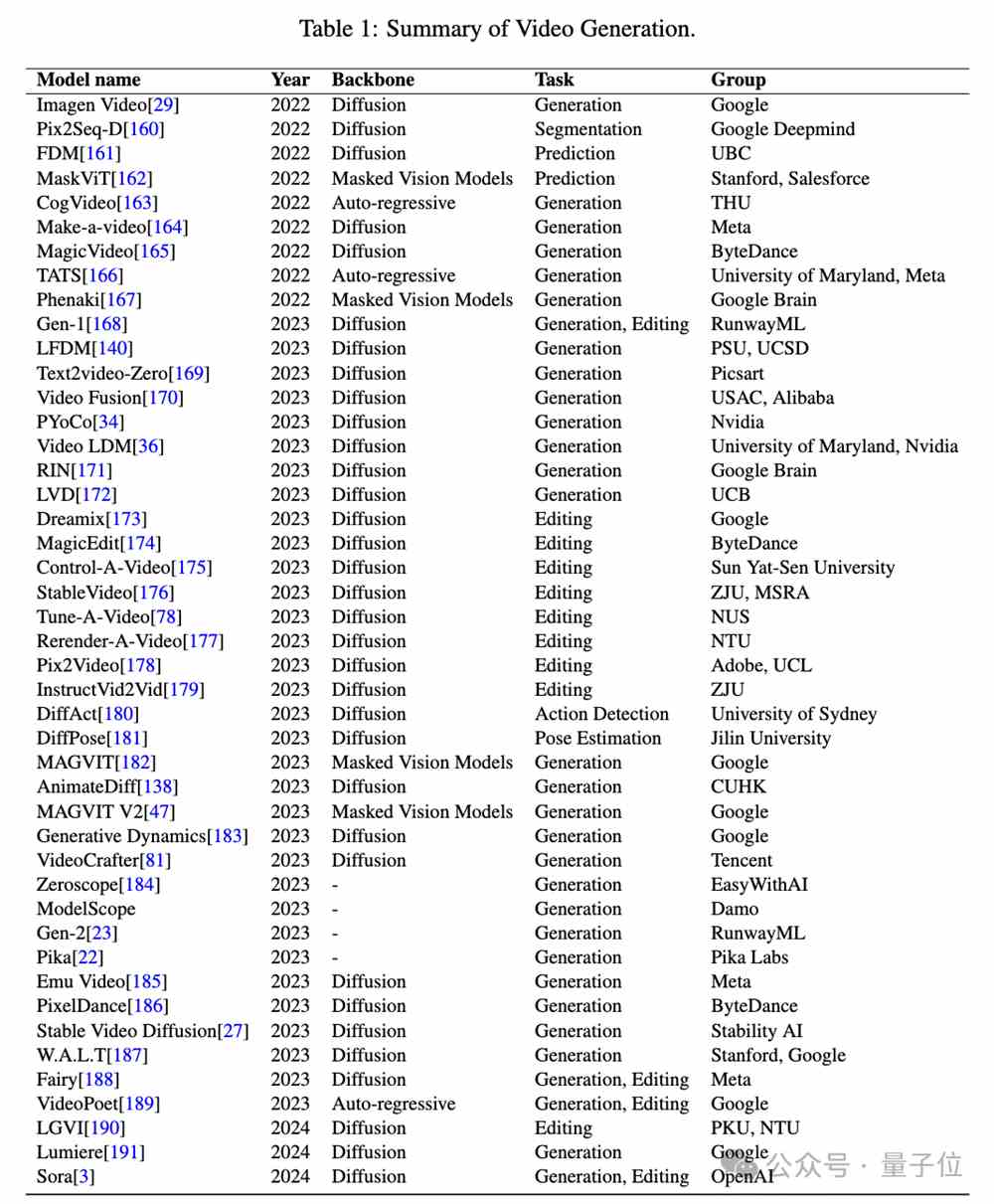
Sora刚发布不久,就被逆向工程“解剖”了?!来自理海大学、微软研究院的华人团队发布了首个Sora相关研究综述,足足有37页。他们基于Sora公开技术报告和逆向工程,对模型背景、相关技术、应用、现存挑战以及文本到视频AI模型未来发展方向进行了全面分析。连计算机视觉领域的AI生成模型发展史、近两年有代表性的视频生成模型都罗列了出来:站长网2024-03-03 21:42:260001Suno正式发布V3音乐生成模型 所有人都可用
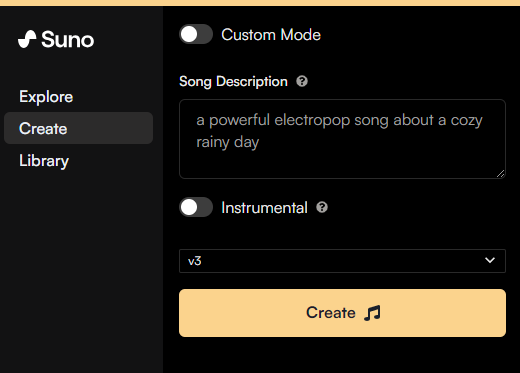
音乐科技领域的创新者Suno在昨晚正式发布了他们备受期待的V3音乐生成模型。这一全新的模型现已面向所有人开放使用,旨在为用户提供更加丰富和高质量的音乐体验。官网地址:https://top.aibase.com/tool/suno-aiV3模型的改进主要体现在以下几个方面:站长网2024-03-23 05:18:230000