几千元训完中文版LLaMA2!Colossal-LLaMA-2把大模型门槛打下来了!
站长网2023-09-25 14:07:480阅
要点:
1、通过词表扩充、数据筛选和多阶段训练策略,在15小时内用几千元成本训练出中文版LLaMA2。
2、中文版LLaMA2在多项中文任务上的表现明显提升,达到同规模模型的先进水平。
3、构建流程、代码和权重均开源,可迁移应用到其他语言和领域,实现低成本大模型训练。
以前,从头预训练大模型被认为需要高达5000万美元的投资,这让很多开发者和中小企业望而却步。而Colossal-LLaMA-2的出现降低了大模型的门槛。
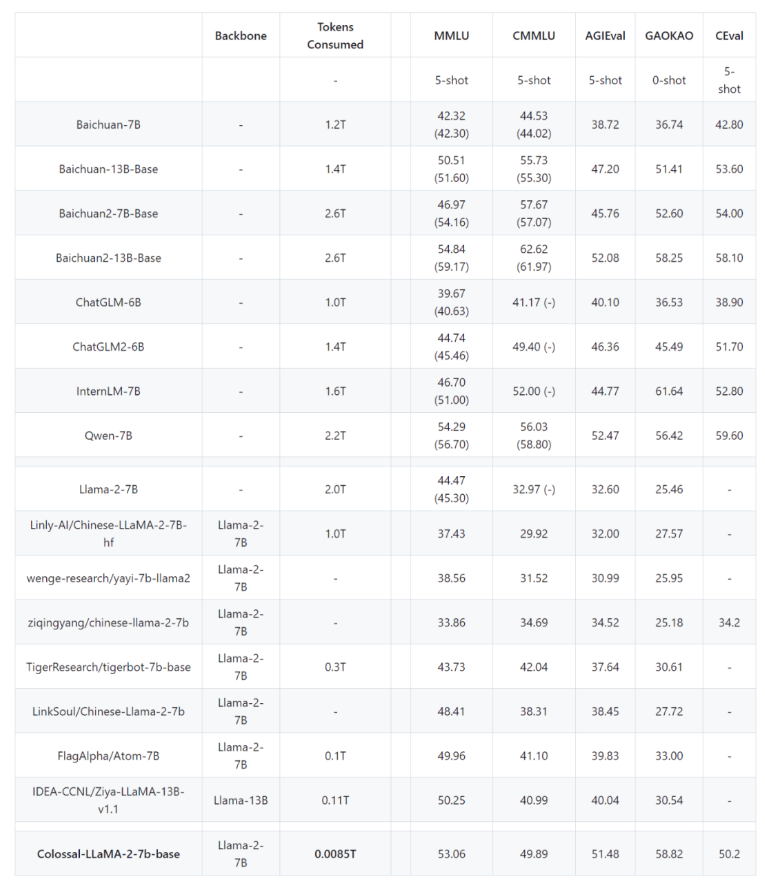
现在,仅需15小时和几千块钱的投入,就能够完成中文LLaMA2大模型的训练,数据规模达到85亿 tokens。这一方案的综合性能达到了开源社区同规模的SOTA模型水平,且完全开源,包括训练流程、代码以及权重。最重要的是,没有商业限制,可以将其应用于各种领域,实现低成本构建从头预训练的大模型。
那么,如何利用Colossal-AI系统和框架,在短时间内用很低的成本构建出表现优异的中文版本LLaMA2模型呢?
首先,通过扩充原英文词表,新增中文词汇,并利用原模型权重智能初始化,实现英文知识迁移。然后,利用严格的数据筛选流程构建高质量增量训练语料。
在训练策略上,设计了多阶段渐进式训练流程,以及均衡的数据分桶策略。最后,构建了完整的评估体系ColossalEval来全面评测模型效果。
在此流程的启发下,仅用15小时和几千元成本,就训出了中文版LLaMA2。该模型在各类中文任务上的表现已达到甚至超过同规模模型的先进水平。
所有训练代码和预训练权重均开源,可以直接应用到其他语言和领域,实现大模型低成本快速构建。背后是Colossal-AI提供的高效并行和异构内存支持等系统优化。该方案业已应用到多个行业领域,构建垂类大模型并取得良好效果。
0000
评论列表
共(0)条相关推荐
讯飞版「Her」横空出世全民开放!百变人设逼真丝滑,情绪价值逆天
【新智元导读】OpenAI的「Her」还是期货,讯飞星火版「Her」就抢先上线了!不仅极速响应自由打断,还情绪价值拉满,各种情感、风格、方言随意切换。熊二被召唤出来的时候,家里的熊孩子直接被硬控了30秒。就在昨天,人类与机器的对话方式,全面升级了!我们在使用一番之后,可谓是大开眼界。比如,让它用天津话讲段相声。您别说,这味儿可太对了!站长网2024-09-02 16:23:230000右脑科技RightBrain AI旗下AI视频创作Video Studio功能开启内测
右脑科技(RightBrainAI)宣布VideoStudioAI视频创作功能开启内测,支持定制视频模型,一键视频风格切换、特效生成、拖拽式视频创作。据悉,北京右脑科技有限公司(RightBrainAI)成立于2022年9月,是一家专注研发AI图像和视频生成的初创公司,致力于将AIGC技术应用于图像及视频领域。站长网2023-08-19 15:46:410000荣耀Magic折叠屏新品10月12日发布 或为Magic Vs2
荣耀手机官方宣布,其新款折叠屏手机——Magic折叠屏新品将于10月12日正式发布,其宣传口号为“实力,不止纸面”。据此前爆料,此次发布的新品应该是传闻已久的荣耀MagicVs2。荣耀MagicVs2将采用稀土镁合金材料,具有重量轻、厚度薄的特点。站长网2023-10-09 08:52:480000文本转语音AI工具哪个好用?Elevenlabs推新版本:支持28种语言 拥有100万用户
文章概要:1.Elevenlabs推出新模型“Eleven多语言v2”,支持28种语言文本转语音。2.与上一个版本相比,新模型实现了更好的语音真实性。3.Elevenlabs计划推出AI语音共享平台,目标受众为媒体、游戏开发商等。最近,Elevenlabs推出了新模型“ElevenMultilingualv2”,可自动识别28种语言,并将文本转换为语音。站长网2023-08-24 23:31:470000苹果 MR 设备采用双接口设计 已进入最后冲刺与供应链拉货阶段
站长之家(ChinaZ.com)4月24日消息:据彭博社MarkGurman最近消息,苹果AR/VR头显将在今年6月的WWDC上发布,并提供两个接口:一个用于数据传输的USB-C接口和一个用于连接电池的专有磁性接口。站长网2023-04-24 11:23:040000