字节发布视觉基础模型ViTamin
字节发布视觉基础模型ViTamin,多项任务实现SOTA,入选CVPR2024
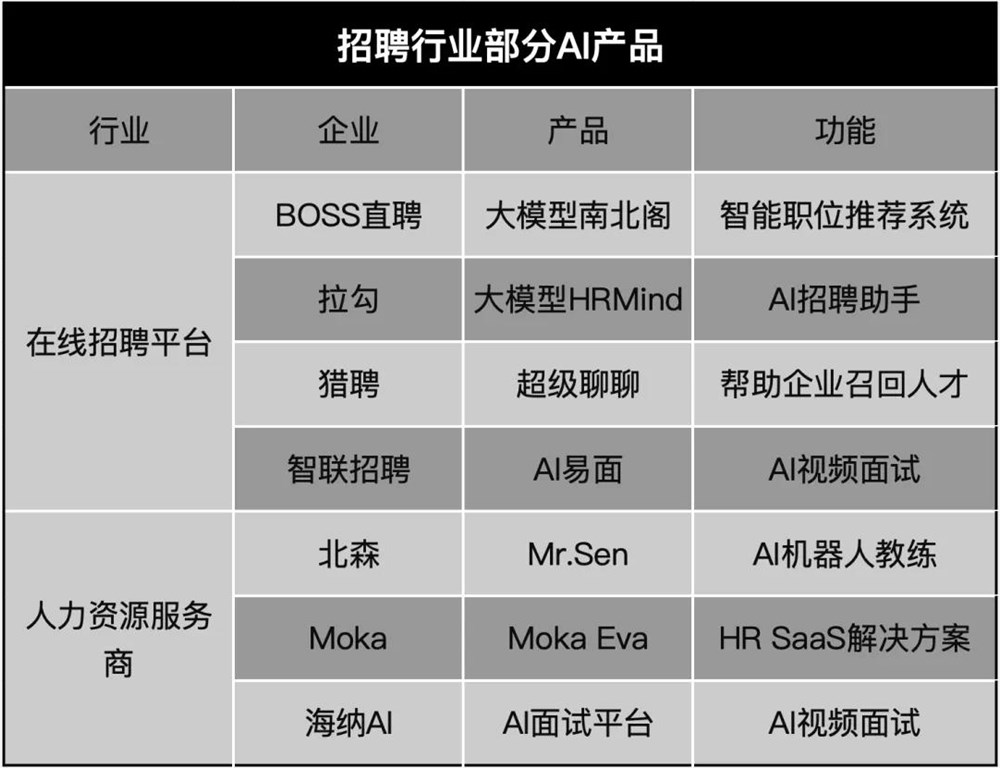
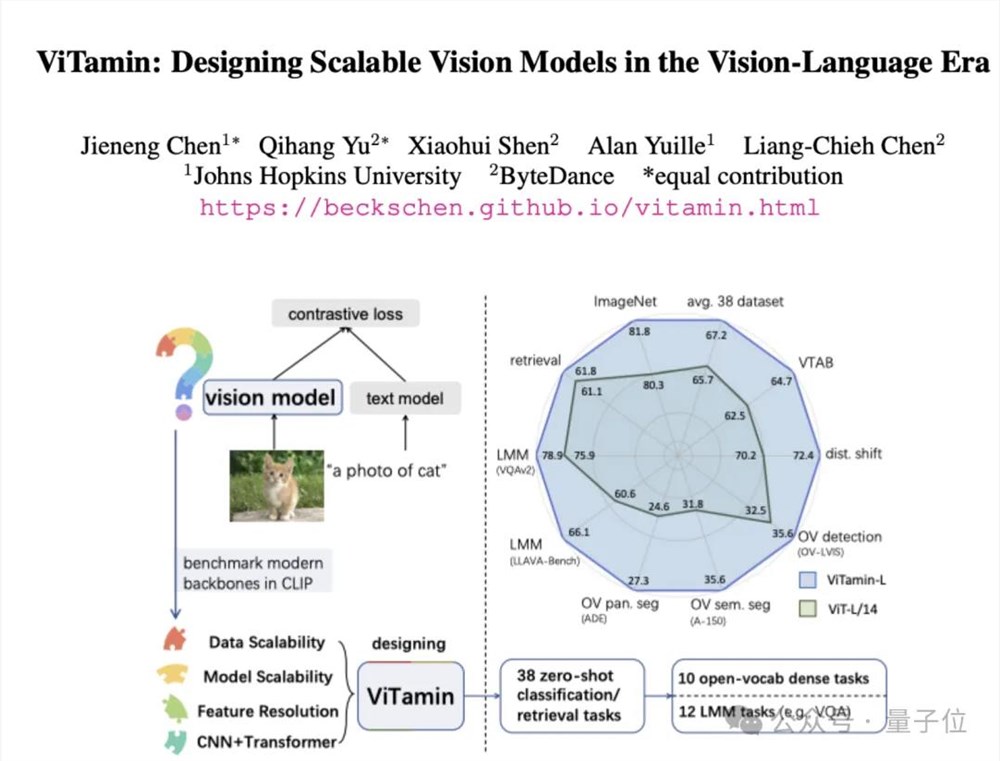
视觉语言模型屡屡出现新突破,但ViT仍是图像编码器的首选网络结构。字节提出新基础模型——ViTamin,专为视觉语言时代设计。在使用相同的数据集和训练方案时,ViTamin在ImageNet零样本准确率上比ViT提高了2.0%。此外在分类、检索、开放词汇检测和分割、多模态大语言模型等60个不同基准上都表现出了良好的结果。站长网2024-04-27 18:52:080001

热点
phi-3安装指南:如何在 MacBook Pro 上微调 phi-3
2024-04-25 21:41:03均价破万!AI让PC快成了奢侈品
2024-04-25 03:04:33小米回应SU7翼子板脱落:车辆高速涉水行驶 仅个例出现
2024-04-25 03:04:33股价飙升!商汤大模型挑战GPT4
2024-04-25 20:01:57雷军:小米 SU7 锁单量超 75723 台 6月月交付将超1万台
2024-04-25 20:00:40TikTok Lite 在欧洲暂停奖励功能 监管机构担忧其可能引发成瘾
2024-04-25 20:00:39扎克伯格表示 Meta 需要数年时间才能从生成式人工智能中盈利
2024-04-25 18:25:20特斯拉市值一夜大涨4028亿 股价飙升超12%
2024-04-25 18:19:25小米回应SU7翼子板脱落:仅个例 均经历过高速涉水
2024-04-25 18:19:25微信发布桌面效率AI工具小微助手 支持类ChatGPT在线聊天问答功能
2024-04-25 18:19:24
关注
小米汽车su7将参加北京车展:雷军亲临现场交流
2024-04-22 08:42:35
华为Pura 70/Pro 今日开售:5499元起!
2024-04-22 08:37:36
微软演示 VASA-1 深度伪造因效果太好不适合向公众发布
2024-04-21 10:54:33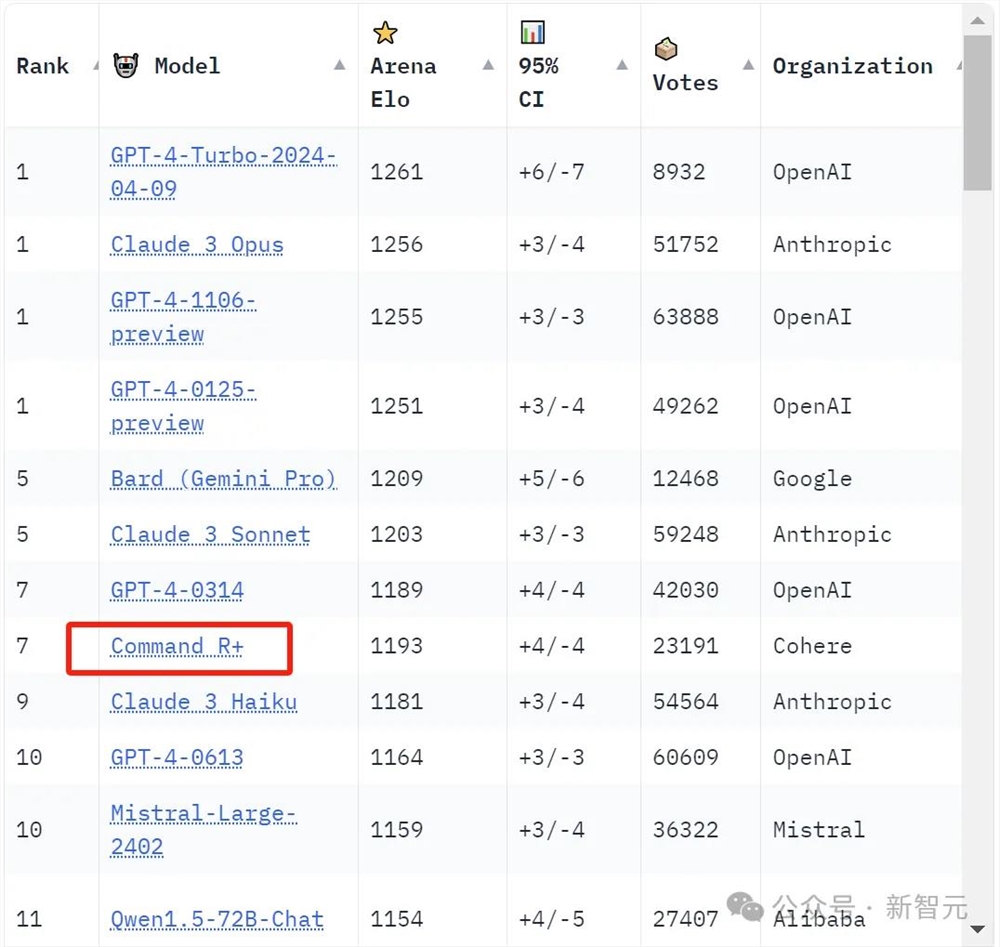
开源模型打败GPT-4!LLM竞技场最新战报,Cohere Command R+上线
2024-04-21 10:39:25
全球独一档!蔚来离车自主换电功能亮相:车辆自动排队换电
2024-04-21 10:21:45
华为小米有对手了 马斯克:特斯拉FSD可能很快落地中国
2024-04-21 10:18:49
再见,AI意识先驱:Daniel Dennett
2024-04-21 10:13:41
开源大模型Llama 3王者归来!最大底牌4000亿参数,性能直逼GPT-4
2024-04-21 10:13:40
周鸿祎:我不是针对李彦宏 开源一定会超过闭源
2024-04-21 10:13:38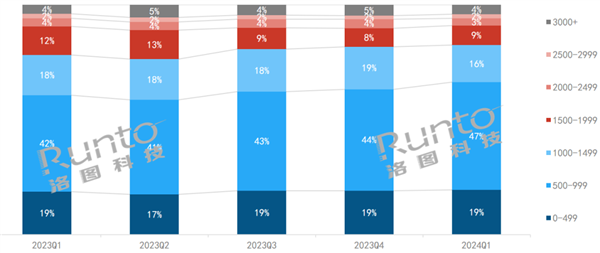
中国显示器越来越便宜 均价已逼近1000元
2024-04-21 10:08:38