清华发布SmartMoE:支持用户一键实现 MoE 模型分布式训练
清华大学计算机系 PACMAN 实验室发布了一种稀疏大模型训练系统 SmartMoE,该系统支持用户一键实现 Mixture-of-Experts(MoE)模型的分布式训练,并通过自动搜索并行策略来提高训练性能。
论文地址:https://www.usenix.org/system/files/atc23-zhai.pdf
项目地址:https://github.com/zms1999/SmartMoE
MoE 是一种模型稀疏化技术,通过将小模型转化为多个稀疏激活的小模型来扩展模型参数量。然而,传统的专家并行技术在训练 MoE 模型时存在性能问题,因为稀疏激活模式导致节点间不规则的 all-to-all 通信增加延迟和计算负载不均。

为了解决这些问题,SmartMoE 系统设计了专家放置策略和自动并行算法。通过对常用并行策略的支持和动态负载均衡,SmartMoE 系统在性能测试中表现出较高的加速比。
该系统的特点包括:
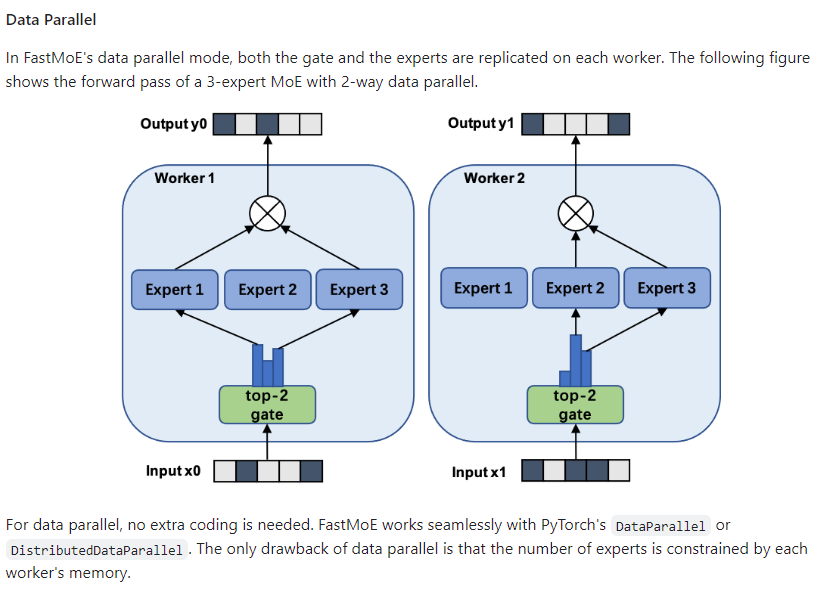
支持常用并行策略:SmartMoE 系统对数据并行、流水线并行、模型并行和专家并行等四种并行策略进行了全面的支持,并允许用户任意组合这些策略。
专家放置策略:为了处理 MoE 模型的动态计算负载,SmartMoE 系统设计了专家放置策略,根据当前负载调整专家的放置顺序,实现节点间的负载均衡。
两阶段自动并行算法:为了提高 MoE 模型复杂混合并行策略的易用性,SmartMoE 系统设计了一套轻量级且有效的两阶段自动并行算法。这个算法将自动并行搜索过程分为训练开始前的搜索和训练过程中的动态调整两个阶段,以减少搜索的开销。
高性能:在性能测试中,SmartMoE 在不同模型结构、集群环境和规模下都表现出优异的性能。相较于之前的 FasterMoE 系统,SmartMoE 能够实现高达1.88倍的加速比。
总之,SmartMoE 是一种可以一键实现高性能 MoE 稀疏大模型分布式训练的系统,具有支持多种并行策略、专家放置策略和两阶段自动并行算法的特点。通过这些特点,SmartMoE 系统能够提高 MoE 模型的易用性和训练性能,助力 MoE 大模型的发展。
网易1.5折甩卖暴雪“分手遗产” 有人狂抢4箱转卖:暴雪国服仍没人接
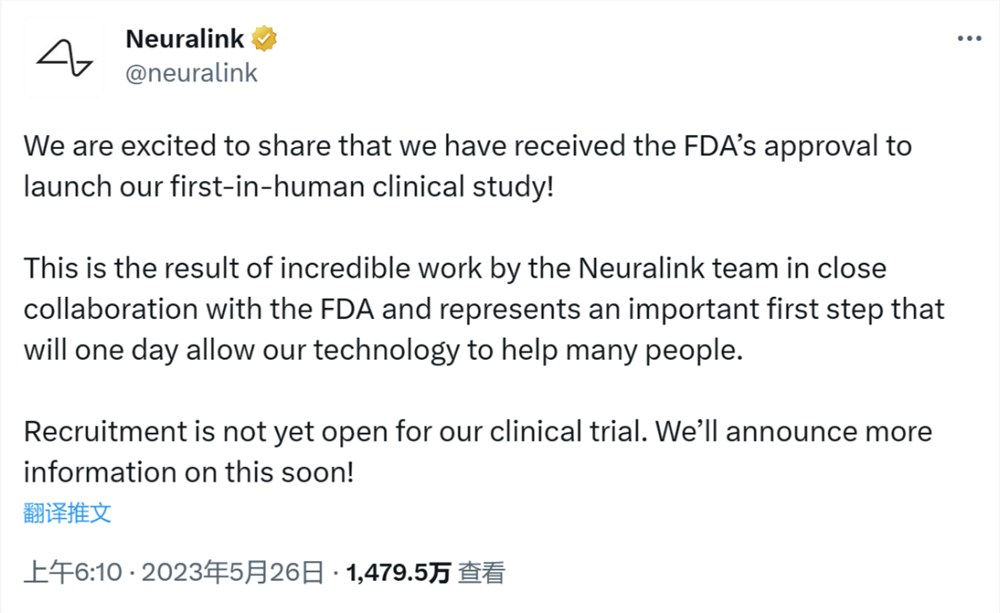
近日,有认证为网易员工的用户在社交平台发帖称,网易杭州公司园区内正以1.5折甩卖暴雪遗留周边,并晒出排队火爆的现场照片,引发关注。该动态评论区中,有网易员工称广州园区也有暴雪周边甩卖活动。一位认证为前阿里巴巴集团员工的用户则表示,抢了很多,包括四箱《守望先锋》的猩猩手办。花60元买的一款书包,当天就在闲鱼以200多元卖了。0000终于!马斯克 Neuralink 获得 FDA 批准,可首次进行人体实验
去年12月,马斯克曾放话:预计脑机接口公司Neuralink将在6个月后,进行大脑芯片的人体试验。彼时,回想起这些年来马斯克在特斯拉、SpaceX上不断“画饼”的行为,许多人对于“6个月”这个说法,不过笑笑而已——可没想到,这个Flag居然真的成了!本周五,Neuralink官方激动发推:“很高兴地告诉大家,我们已获得FDA的批准,可以启动我们的首次人体临床研究!”站长网2023-05-27 10:11:200001微信已把帐号改为账号 此前QQ、抖音等已经更正
据每日经济新闻报道,目前,在安卓系统手机登录微信时,微信相关页面和表述中的“帐号”已经改为“账号”。据悉,去年4月有媒体报道披露,多个社交软件和平台的用户登录页面、用户协议、隐私政策等相关表述中多处使用的是“帐号”。多位专家接受采访时表示,“帐号”为旧时用法,现在正确的表述是“账号”。站长网2023-07-28 10:44:030001人工智能初创公司 SambaNova 推出专为更高质量 AI 设计的新芯片:可运行比 OpenAI 的 ChatGPT 高级版大两倍以上的模型
站长之家(ChinaZ.com)9月20日消息:人工智能芯片初创公司SambaNovaSystems在周二推出了一款新的半导体芯片,旨在让其客户以更低的总成本使用更高质量的人工智能模型。这家位于加利福尼亚州帕洛阿尔托的公司表示,SN40L芯片旨在运行比OpenAI的ChatGPT高级版使用的大两倍以上的模型。站长网2023-09-20 09:33:500000美国部分学校鼓励使用ChatGPT,确保学生不会落伍
本文概要:1.美国有些学校鼓励学生使用生成人工智能工具,并教授如何正确使用。2.AI技术的应用预计将继续增加,学校担心忽视或限制使用将对学生不利。3.一些学校雇佣外部专家,培训教师和学生使用AI工具。学校教育工作者最初对AI技术的反应是禁止使用,据CNN报道但现在越来越多的学校开始鼓励学生使用生成人工智能工具,如ChatGPT。站长网2023-08-21 14:36:280000