斯坦福博士独作!大模型训练速度再翻倍,还官宣加入明星创业公司当首席科学家
现有大语言模型的训练和推理速度,还能再快一点——
快多少?2-4倍。
各种大模型都在用的FlashAttention今天正式发布第2代并开源,所有Transformer架构的模型都可使用它来加速。
一代方法去年6月发布,无需任何近似即可加速注意力并减少内存占用。
现在,FlashAttention-2将它再度升级,使其核心注意力操作的速度再提高2倍,端到端训练Transformer时的速度再提高1.3倍,并可在英伟达A100上训练时实现72%的模型FLOP利用率(一般模型都在50%上下)。
鉴于现在炼一个大语言模型的成本高达数千万美元,FlashAttention-2这一系列操作直接就能帮我们省掉数百万(美元)!
网友惊得脏话都出来了(狗头):
目前,这个项目已在GitHub上收获4.4k标星。
与此同时,我们注意到,它的一作已经完成斯坦福博士学位并加盟大模型创业公司Together AI。
具体实现
据介绍,一代FlashAttention是一种对注意力计算重新排序的算法,它利用经典方法如tiling(切片)来显著加快计算速度,并将序列长度的内存使用量从二次方减为线性。
其中tiling方法指的是将输入块从HBM(GPU内存)加载到SRAM(快速缓存),然后对该块进行attention操作,再更新HBM中的输出。
对HBM的反复读写就成了最大的性能瓶颈。

正是这种通过避免将大型中间注意力矩阵写入HBM的方法,FlashAttention减少了内存读/写量,从而带来2-4倍的时钟时间加速。
然而,这个算法仍然存在一些低效率的问题,导致它仍然不如优化矩阵乘法(GEMM)运算来得快,最终仅达到理论最大FLOPs/s的25-40%(例如在A100上最多124TFLOPs/s)。
究其原因,还是因为不同线程块之间的工作和GPU上的wrap划分不理想。
在此,FlashAttention-2进行了三方面的改进。
首先,在基础算法上,减少非matmul(矩阵乘法)FLOP的数量。
一层原因是由于现代GPU具有专门的计算单元,matmul速度更快。例如A100上FP16/BF16matmul的最大理论吞吐量为312TFLOPs/s,但非matmul FP32的理论吞吐量仅为19.5TFLOPs/s。
另一层原因是价格考量,毕竟每个非matmul FLOP比matmul FLOP贵16倍。同时在matmul FLOP上花费尽可能多的时间也能保持高吞吐量。
为此,作者重写了FlashAttention中的softmax trick,无需更改输出即可减少重新缩放操作的数量,以及边界检查和因果屏蔽操作(causal masking operation)。
其次,当batch size较小时并行化以获得更高的占用率。
FlashAttention一代在batch size和注意力头数量上进行并行化。
由于它使用1个线程块来处理1个注意力头,总共就有(batch_size*注意力头数)个线程块,每个线程块被安排在流式多处理器(SM)上运行。
当在像A100这样有108个SM处理器上操作时,如果线程块很多比如>=80,这样的调度安排就很有效。
而在长序列的情况下,也就是batch size和头数量很少(小)时,就需要在序列长度维度上另外进行并行化来更好地利用GPU上的多处理器了。
这个改进也是FlashAttention-2速度显著提升的一大原因。
最后,改进工作分区。
在线程块内,我们必须确定如何在不同的warp之间划分工作。通常是每个块使用4或8个warp,现在,作者改进了这一方式,来减少不同warp之间的同步和通信量,从而减少共享内存读写操作。
如下图左所示,FlashAttention一代的做法是将K和V分割到4个warp上,同时保持Q可被所有warp访问。这样的后果是所有warp都需要将其中间结果写入共享内存,然后进行同步再将中间结果相加,非常低效,减慢了FlashAttention中的前向传播速度。
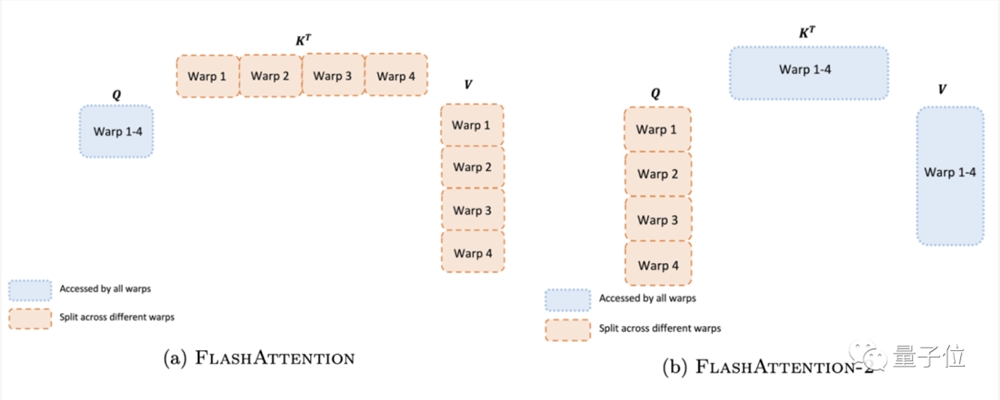
而在FlashAttention-2中,作者将Q分为四个warp,同时保证所有warp都可访问K和V。
每个warp执行矩阵乘法获得Q K^T的切片后,只需与V的共享切片相乘即可获得相应的输出。也就是说warp之间不需要通信,那么共享内存读写操作就少了很多,速度也就提上来了。
除了这三个大改进,FlashAttention-2还有两个小改动:
一是注意力头数从128增至256,这意味着GPT-J、CodeGen和CodeGen2以及StableDiffusion1.x等模型都可以使用 FlashAttention-2来进行加速和内存节省了;
二是支持多查询注意力(MQA)和分组查询注意力(GQA)。
实验评估
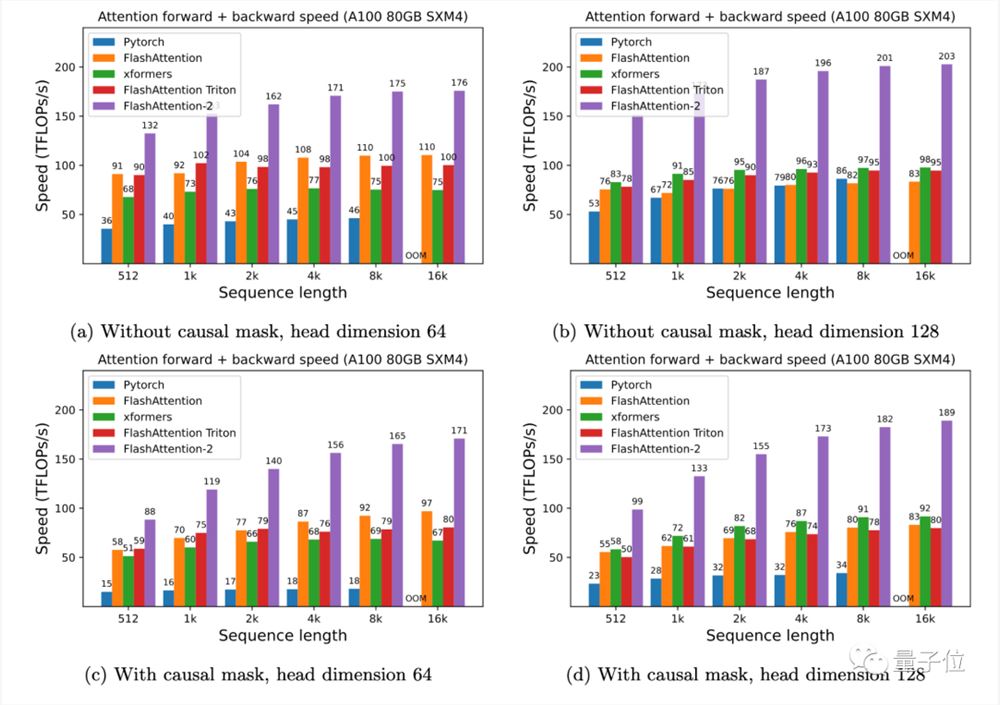
作者在A10080GB SXM4GPU上对不同配置(有无causal mask,头数量64或128)下的运行时间进行了测量。
结果发现:
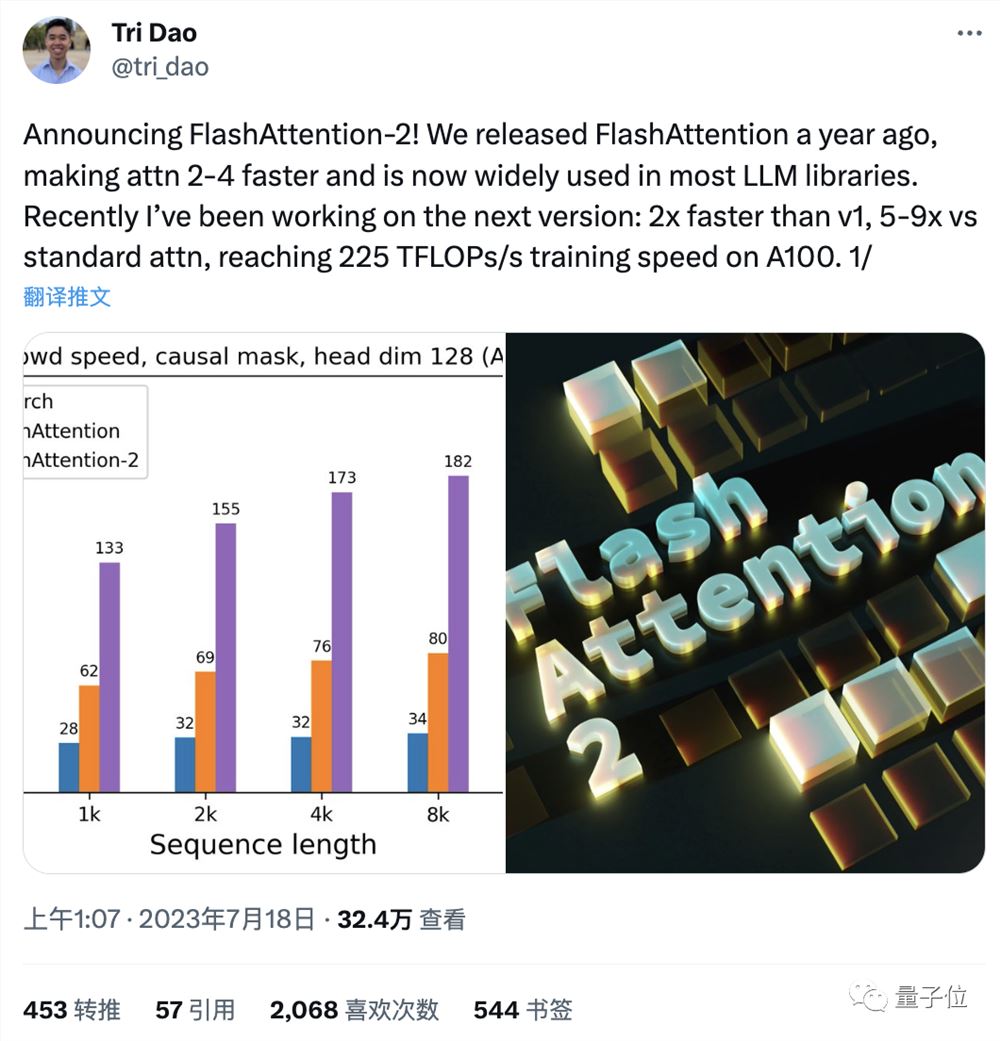
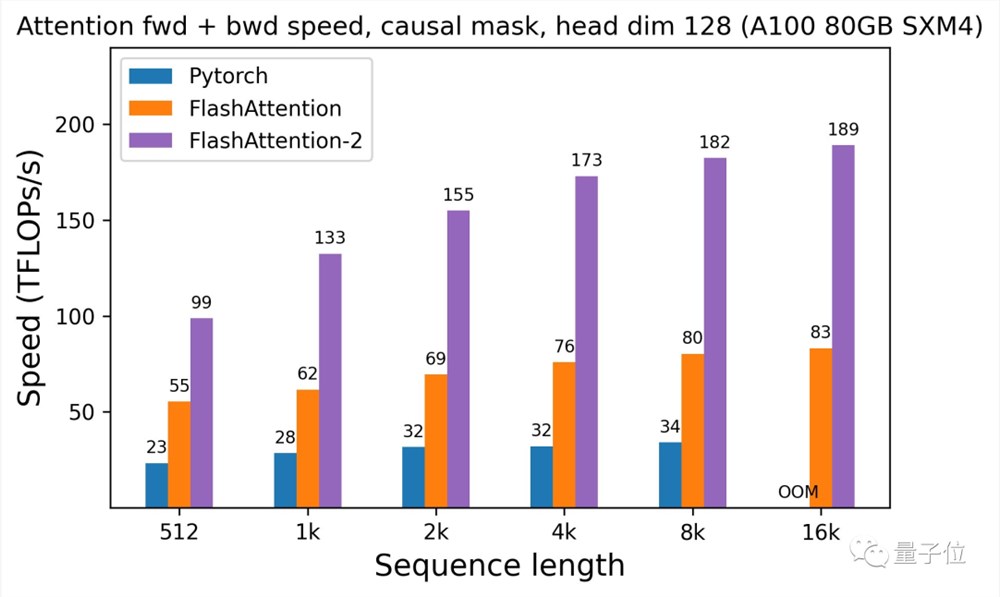
FlashAttention-2比FlashAttention(包括xformers库和Triton中的其他实现)快大约2倍,这也意味我们可以用与之前训练8k上下文模型相同的价格来训练具有16k上下文的模型了(也就是模型上下文长度加倍)。
而与PyTorch中的标准注意力实现相比,FlashAttention-2的速度最高可达9倍。
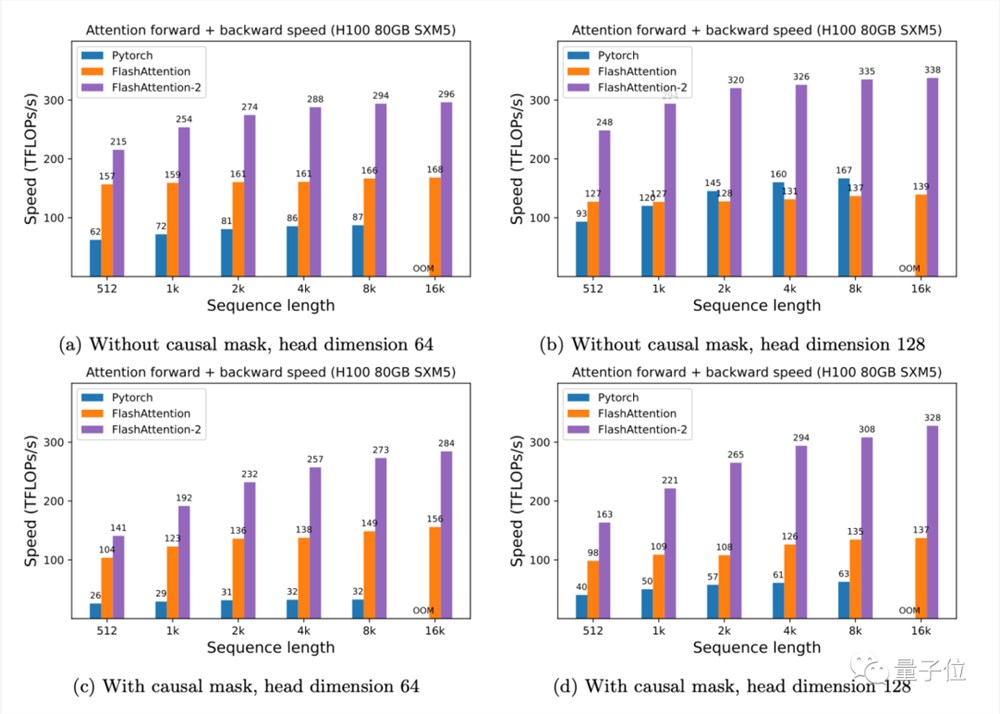
此外,有了FlashAttention-2,我们只需在H100GPU上运行相同的实现(不使用特殊指令利用TMA和第四代Tensor Core等新硬件功能),训练速度就可以跑到高达335TFLOPs/s的成绩。
以及当用于端到端训练GPT式模型时,FlashAttention-2还能在A100上实现高达225TFLOPs/s的速度(模型FLOPs利用率达72%)。这与已经优化程序足够高的FlashAttention相比,速度再提高了1.3倍。

一作加入大模型创业公司
FlashAttention-2论文仅显示一位作者:Tri Dao。他也是FlashAttention一代的两位共同作者之一。

据了解,Tri Dao的研究方向为机器学习和系统的交叉领域,去年拿下ICML2022杰出论文亚军奖。
最近他刚刚获得斯坦福大学计算机科学博士学位,即将上升普林斯顿大学助理教授,并已宣布加盟生成式AI创业公司Together AI(该司主要目标构建一个用于运行、训练和微调开源模型的云平台)担任首席科学家。
One More Thing
最后,有网友发现,除了FlashAttention-2,最近还有一系列类似成果,包括DeepSpeed的ZeRO 、马萨诸塞大学de ReLoRA。
它们都是用于加速大型模型预训练和微调,这些研究成果让他觉得:
未来在低vram低带宽的消费显卡上训练大模型,似乎已不是在做梦了。
大家认为呢?
论文地址:
https://tridao.me/publications/flash2/flash2.pdf
博文地址:
https://princeton-nlp.github.io/flash-atttention-2/
GitHub主页:
https://github.com/Dao-AILab/flash-attention
参考链接:
[1]https://twitter.com/tri_dao/status/1680987577913065472?s=20
[2]https://twitter.com/togethercompute/status/1680994294625337344?s=20
[3]https://twitter.com/main_horse/status/1681041183559254017?s=20
—完—
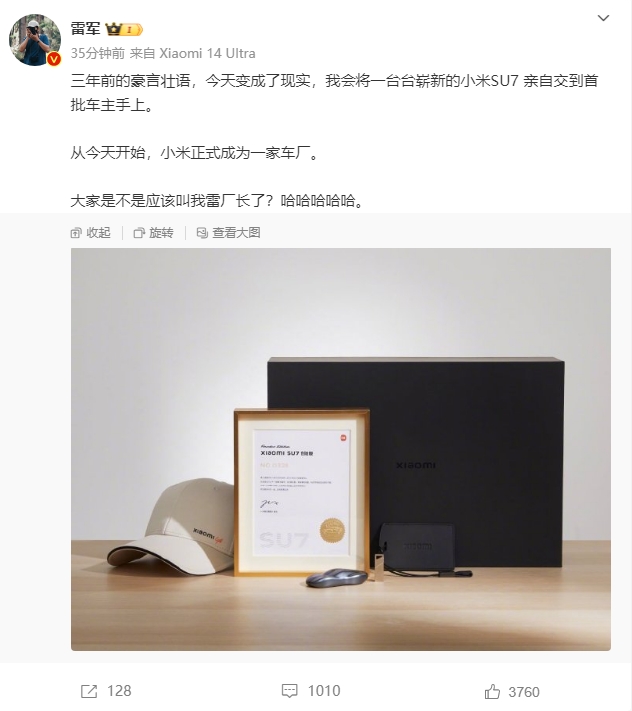
小米首批SU7开启交付 雷军:小米正式成为一家车厂
小米集团董事长雷军在微博上兴奋宣布:“三年前的豪言壮语,今天变成了现实,我会将一台台崭新的小米SU7亲自交到首批车主手上。从今天开始,小米正式成为一家车厂。大家是不是应该叫我雷厂长了?哈哈哈哈哈。”据了解,小米公司昨日已对外公布,今日将在北京亦庄的小米汽车工厂隆重举办小米SU7的首批交付仪式。与此同时,全国范围内的28座城市交付中心也定于4月3日同步启动交付工作。站长网2024-04-08 12:45:260000抢攻 AI 的大厂先从哪些场景下手?
变化正在快速发生!从OpenAI的ChatGPT-4聊天窗口转移到你我每天的工作中。先有微软的Copilot,后有国内百度、阿里、金山、字节等涉及办公领域大厂新发布的各种办公智能AI应用。ChatGPT的能力正在与办公场景发生化学反应,深入到具体细分场景。站长网2023-04-21 18:11:220000图库图片提供商Getty Images要求在英国禁售Stability AI系统
据路透社报道,日期为5月12日的法庭文件显示,图库图片提供商GettyImages(盖蒂图片社)已向伦敦高等法院申请禁令,以阻止AI公司StabilityAI在英国出售其AI图像生成系统。站长网2023-06-03 16:23:160000千呼万唤的可灵网页版来了!基础模型重磅升级,新功能“炸场”WAIC
“这可能是本届WAIC上欢呼声最多的一场发布”在刚刚闭幕的世界人工智能大会(WAIC)上,快手晒出了可灵发布一个月以来的成绩单:“超50万人申请,已开放给超30万用户使用,生成超700万条短视频。”作为全球首个用户可用的真实影像级视频生成大模型,可灵一经问世便引发了强烈反响,连外国网友都纷纷投来了羡慕的目光……站长网2024-07-08 11:07:360000双11是怎么被“拉近”的?
以双11为代表的零售线上化,是过去十多年中国零售商业的大趋势。但到了今年双11,线上零售略显疲态,线下本地商家搭乘即时零售的东风,成为新的驱动力。大促期间,各大电商平台纷纷打出低价牌,并搭配官方直降等玩法。轰轰烈烈的价格战之后,电商平台并没有像往年那样晒出双11成绩单,而是重点宣传其他维度的亮点,比如有多少个品牌交易额破亿、破十亿等。站长网2023-11-15 18:08:580000