爆火Sora参数规模仅30亿?谢赛宁等大佬技术分析来了
就说Sora有多火吧。
生成的视频上线一个、疯传一个。

作者小哥新上传的效果,很快引来围观。

失败案例都让人看得上瘾。

将近1万人点赞。

学术圈更炸开锅了,各路大佬纷纷开麦。
纽约大学助理教授谢赛宁(ResNeXt的一作)直言,Sora将改写整个视频生成领域。
英伟达高级研究科学家Jim Fan高呼,这就是视频生成的GPT-3时刻啊!
尤其在技术报告发布后,讨论变得更加有趣。因为其中诸多细节不是十分明确,所以大佬们也只能猜测。
包括“Sora是一个数据驱动的物理引擎”、“Sora建立在DiT模型之上、参数可能仅30亿”等等。
所以,Sora为啥能如此惊艳?它对视频生成领域的意义是?这不,很快就有了一些可能的答案。
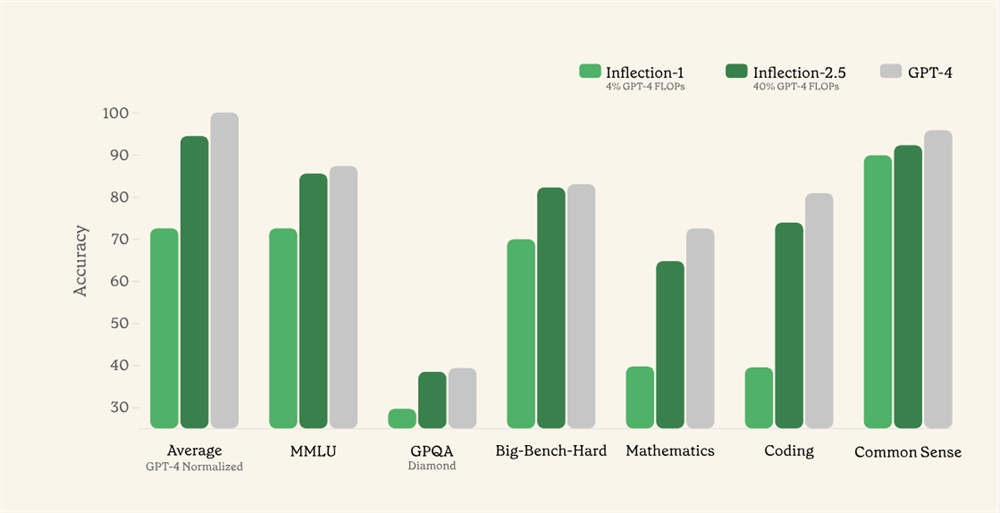
视频生成的GPT-3时刻
总的来说,Sora是一个在不同时长、分辨率和宽高比的视频及图像上训练而成的扩散模型,同时采用了Transformer架构,也就是一种“扩散型Transformer”。

关于技术细节,官方报告简单提了以下6点:
一是视觉数据的“创新转化”。
与大语言模型中的token不同,Sora采用的是“Patches(补片)”来统一不同的视觉数据表现形式。
如下图所示,在具体操作中,模型先将视频压缩到低维潜空间中,然后将它们表示分解为时空补片,从而将视频转换为补片。(啊这,说了又仿佛什么都没说)

二是训练了一个视频压缩网络。
它可以降低视觉数据维度,输入视频,输出时空上压缩的潜表示。
Sora就在这上面完成训练。相应地,OpenAI也训练了一个专门的解码器。
三是时空补片技术(Spacetime latent patches)。
给定一个压缩的输入视频,模型提取一系列时空补片,充当Transformer的token。正是这个基于补片的表示让Sora能够对不同分辨率、持续时间和长宽比的视频和图像进行训练。
在推理时,模型则通过在适当大小的网格中排列随机初始化的补片来控制生成视频的大小。
四是扩展Transformer也适用于视频生成的发现。
OpenAI在这项研究中发现,扩散型Transformer同样能在视频模型领域中完成高效扩展。
下图展示出随着训练资源的增加,样本质量明显提升(固定种子和输入条件)。

五是视频多样化上的一些揭秘。
和其他模型相比,Sora能够hold住各种尺寸的视频,包括不同分辨率、时长、宽高比等等。

也在构图和布局上优化了更多,如下图所示,很多业内同类型模型都会盲目裁剪输出视频为正方形,造成主题元素只能部分展示,但Sora可以捕捉完整的场景:

报告指出,这都要归功于OpenAI直接在视频数据的原始尺寸上进行了训练。
最后,是语言理解方面上的功夫。
在此,OpenAI采用了DALL·E3中引入的一种重新标注技术,将其应用于视频。
除了使用描述性强的视频说明进行训练,OpenAI也用GPT来将用户简短的提示转换为更长的详细说明,然后发送给Sora。
这一系列使得Sora的文字理解能力也相当给力。
关于技术的介绍报告只提了这么多,剩下的大篇幅都是围绕Sora的一系列效果展示,包括文转视频、视频转视频,以及图片生成。

可以看到,诸如其中的“patch”到底是怎么设计的等核心问题,文中并没有详细讲解。
有网友吐槽,OpenAI果然还是这么地“Close”(狗头)。
正是如此,各路大佬和网友们的猜测也是五花八门。
谢赛宁分析:
1、Sora应该是建立在DiT这个扩散Transformer之上的。
简而言之,DiT是一个带有Transformer主干的扩散模型,它= [VAE 编码器 ViT DDPM VAE 解码器]。
谢赛宁猜测,在这上面,Sora应该没有整太多花哨的额外东西。
2、关于视频压缩网络,Sora可能采用的就是VAE架构,区别就是经过原始视频数据训练。
而由于VAE是一个ConvNet,所以DiT从技术上来说是一个混合模型。

3、Sora可能有大约30亿个参数。

谢赛宁认为这个推测不算不合理,因Sora可能还真并不需要人们想象中的那么多GPU来训练,如果真是如此,Sora的后期迭代也将会非常快。
英伟达AI科学家Jim Fan则认为:
Sora应该是一个数据驱动的物理引擎。
Sora是对现实或幻想世界的模拟,它通过一些去噪、梯度下降去学习复杂渲染、“直觉”物理、长镜头推理和语义基础等。
比如这个效果中,提示词是两艘海盗船在一杯咖啡里航行厮杀的逼真特写视频。
Jim Fan分析,Sora首先要提供两个3D资产:不同装饰的海盗船;必须在潜在空间中解决text-to-3D的隐式问题;并且要两艘船避开彼此的路线,兼顾咖啡液体的流体力学、保持真实感、带来仿佛光追般的效果。

有一些观点认为,Sora只是在2D层面上控制像素。Jim Fan明确反对这种说法。他觉得这就像说GPT-4不懂编码,只是对字符串进行采样。
不过他也表示,Sora还无法取代游戏引擎开发者,因为它对于物理的理解还远远不够,仍然存在非常严重的“幻觉”。

所以他提出Sora是视频生成的GPT-3时刻。
回到2020年,GPT-3不是一个很完美的模型,但是它有力证明了上下文学习的重要性。所以不要纠结于GPT-3的缺陷,多想想后面的GPT-4。

除此之外,还有胆大的网友甚至怀疑Sora用上了虚幻引擎5来创建部分训练数据。

他甚至挨个举例分析了好几个视频中的效果以此佐证猜想:

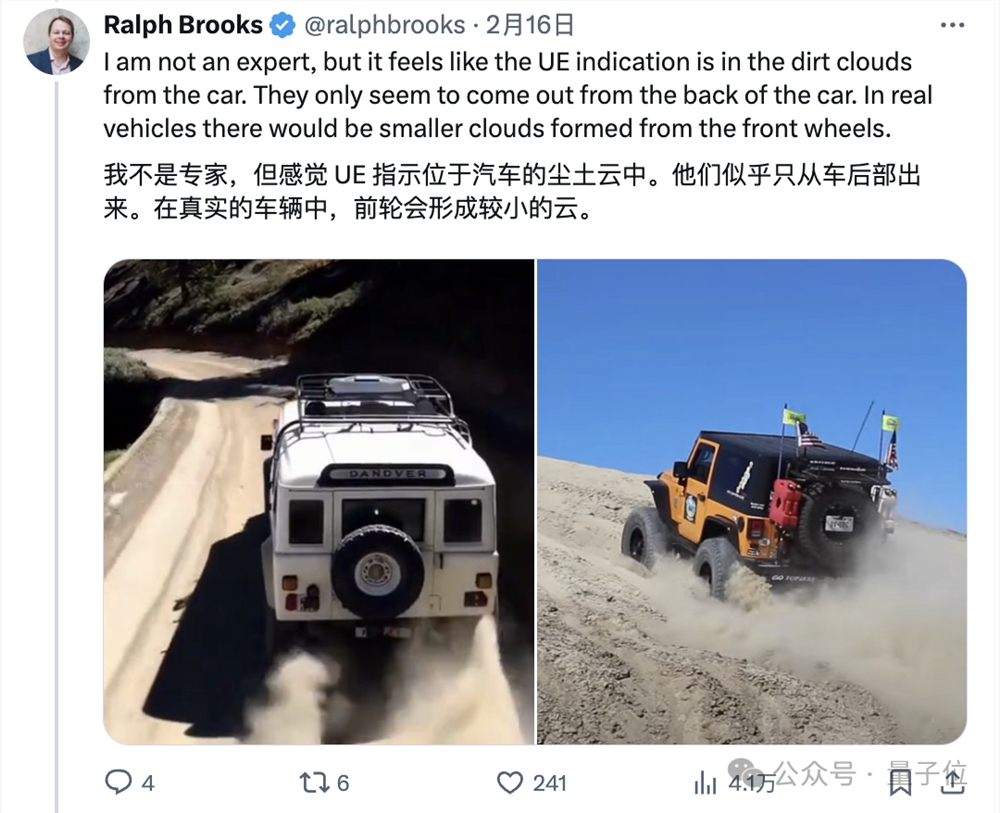
不过反驳他的人也不少,理由包括“人走路的镜头明显还是奇怪,不可能是引擎的效果”、“YouTube上有数十亿小时的各种视频,ue5的用处不大吧”……

如此种种,暂且不论。
最后,有网友表示,尽管不对OpenAI放出更多细节抱有期待,但还是很想知道Sora在视频编码、解码,时间插值的额外模块等方面是不是有创新。

OpenAI估值达800亿美元
在Sora引发全球关注的同时,OpenAI的估值也再次拉高,成为全球第三高估值的科技初创公司。
随着最新一要约收购完成,OpenAI的估值正式达到800亿美元,仅次于字节跳动和SpaceX。
这笔交易由风投公司Thrive Capital牵头,外部投资者可以从一些员工手中购买股份,去年年初时OpenAI就完成过类似交易,使其当时的估值达到290亿美元。
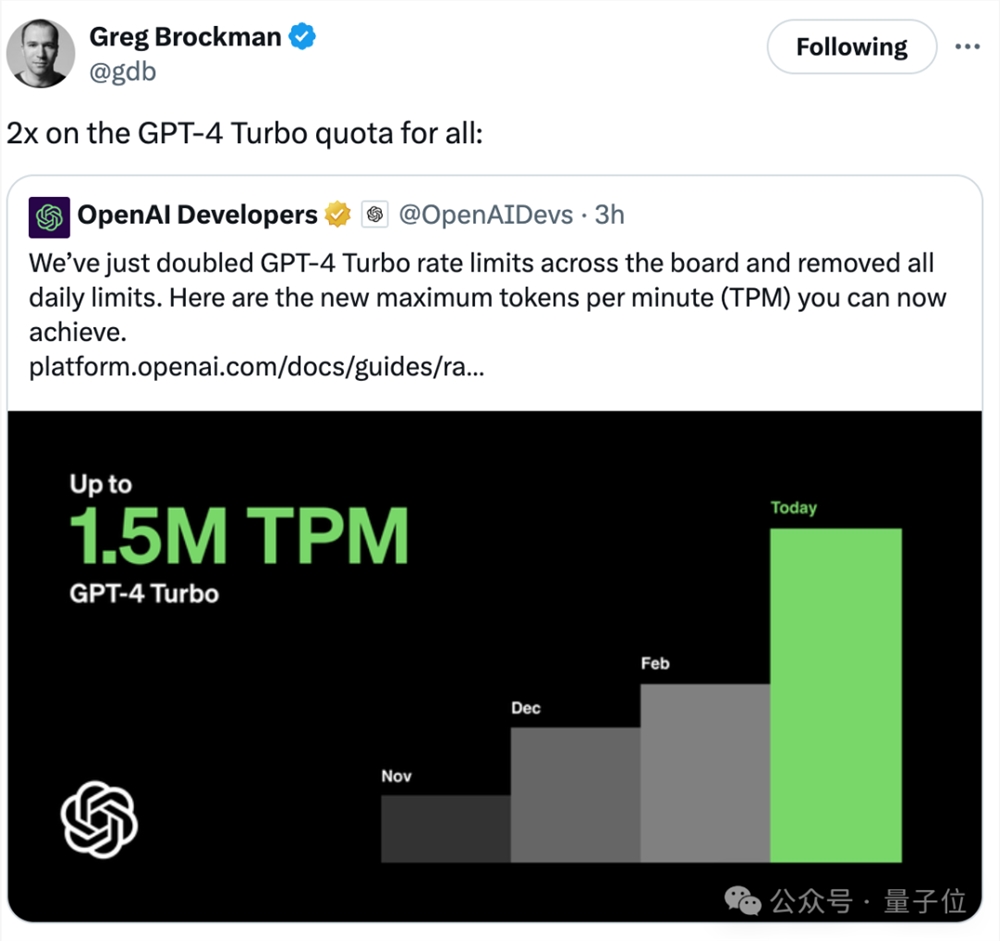
而在Sora发布后,GPT-4Turbo也大幅降低速率限制,提高TPM(每分钟最大token数量),较上一次实现2倍提升。
总裁Brockman还亲自带货宣传。
但与此同时,OpenAI申请注册“GPT”商标失败了。
理由是“GPT”太通用。
One More Thing
值得一提的是,有眼尖的网友发现,昨天Stability AI也发布了SVD1.1。
但似乎在Sora发布不久后火速删博。
有人锐评,这不是翻版汪峰么?不应该删,应该返蹭个热度。
这还玩个p啊。

还有人感慨,Sora一来,立马就明白张楠为啥要聚焦剪映了。

以及卖课大军也闻风而动,把商机拿捏死死的。

参考链接:
[1]https://openai.com/research/video-generation-models-as-world-simulators
[2]https://twitter.com/DrJimFan/status/1758210245799920123
[3]https://x.com/sainingxie/status/1758433676105310543?s=20
[4]https://twitter.com/charliebholtz/status/1758200919181967679
[5]https://www.reuters.com/technology/openai-valued-80-billion-after-deal-nyt-reports-2024-02-16/
—完—
AI需求带来爆炸式增长!数据公司Palantir四季度收入增长20%创新高
**划重点:**1.💼公司收入:第四季度同比增长20%,达到6.08亿美元。2.🚀CEO观点:Palantir首席执行官AlexKarp表示,美国对大型语言模型的需求“持续不减”。3.💹股价表现:财报公布后,Palantir股价在盘后交易中大涨超过19%。站长网2024-02-06 11:39:350000小红书进军本地生活市场,即将上线团购功能
据极客公园报道,小红书开始招募本地生活的店铺、餐饮商家和服务商,部分商家已经加入内测。这标志着小红书在本地生活领域采取了最大的行动。不久后,小红书将推出团购功能,实现本地餐饮从内容种草到交易的闭环。用户可以从笔记右下角的商品笔记中直接购买团购套餐或到店消费。针对商家和达人,小红书已经开展了扶持计划。站长网2023-04-27 16:39:330001爱奇艺CEO龚宇谈AI 称影视行业最后才会被AI取代
在今日的爱奇艺世界大会上,爱奇艺创始人兼CEO龚宇指出,爱奇艺在过去几年经历了一个痛苦阶段,但是影视行业最艰难的时期已经过去了。爱奇艺会坚持长期主义,以作品为唯一价值点,专注于做自己擅长的事,并避免做情怀和野心的事情。公司将奋力追求高质量增长,实现营收利润双增长,持续提升作品数量和质量,而不是一味追求单纯的增长。龚宇认为,对于爱奇艺来说,跑马圈地的增长已经不再适用。站长网2023-05-10 11:15:170000微软推出机器学习库GPT-RAG
要点:GPT-RAG解决了将大型语言模型(LLMs)集成到企业环境中的挑战,通过使用检索增强生成(RAG)模式提供了企业级参考架构。GPT-RAG具有强大的安全框架和零信任原则,通过Azure的网络和安全功能确保对敏感数据的谨慎处理。该解决方案具备自动扩展功能,利用Azure服务适应波动工作负载,同时通过综合的可观测性系统提供系统性能的监测和分析,以支持连续改进。站长网2023-12-19 17:10:550001Jasper公司收购Stability AI旗下的AI图像平台Clipdrop
**划重点:**1.🤝Jasper公司成功收购StabilityAI旗下的ClipdropAI图像平台。2.🛠️Clipdrop提供强大的AI图像编辑工具,现在企业客户可通过JasperAPI访问,消费者可在Clipdrop.co购买独立版本。站长网2024-02-26 10:14:220001