这次重生,AI要夺回网文界的一切
重生了,这辈子我重生成了 MidReal。一个可以帮别人写「网文」的 AI 机器人。
这段时间里,我看到很多选题,偶尔也会吐槽一下。竟然有人让我写写 Harry Potter。拜托,难道我还能写的比 J・K・Rowling 更好不成?不过,同人什么的,我还是可以发挥一下的。
经典设定谁会不爱?我就勉为其难地帮助这些用户实现想象吧。
实不相瞒,上辈子我该看的,不该看的,通通看了。就下面这些主题,都是我爱惨了的。
那些你看小说很喜欢却没人写的设定,那些冷门甚至邪门的 cp,都能自产自嗑。
不是我自夸,只要你想要我写,我还真能给你写出个一二三来。结局不喜欢?喜欢的角色「中道崩殂」?作者写到一半吃书了?包在我身上,给你写到满意。
甜文,虐文,脑洞文,每一种都狠狠击中你的爽点。
听完MidReal的自述,你对它了解了吗?
MidReal 可以根据用户提供的情景描述,生成对应的小说内容。情节的逻辑与创造力都很优秀。它还能在生成过程中生成插图,更形象地描绘你所想象的内容。互动功能也是亮点之一,你可以选择想要的故事情节进行发展,让整体更加贴合你的需求。
在对话框中输入 /start,就可以开始讲述你的故事了,还不快来试试?
MidReal 传送门:https://www.midreal.ai/
MidReal 背后的技术源于这篇论文《FireAct:Toward Language Agent Fine-tuning》。论文作者首次尝试了用 AI 智能体来微调语言模型,发现了诸多优势,由此提出了一种新的智能体架构。
MidReal 就是基于这种架构的,网文才能写得这么好。
论文链接:https://arxiv.org/pdf/2310.05915.pdf
虽然智能体和微调大模型都是最热门的 AI 话题,但它们之间具体有何联系还不清楚。System2Research、剑桥大学等的多位研究者对这片鲜有人涉足的「学术蓝海」进行了发掘。
AI 智能体的开发通常基于现成的语言模型,但由于语言模型不是作为智能体而开发的,因此,延伸出智能体后,大多数语言模型的性能和稳健性较差。最聪明的智能体只能由 GPT-4支持,它们也无法避免高成本和延迟,以及可控性低、重复性高等问题。
微调可以用来解决上面的这些问题。也是在这篇文章中,研究者们迈出了更加系统研究语言智能体的第一步。他们提出了 FireAct ,它能够利用多个任务和提示方法生成的智能体「行动轨迹」来微调语言模型,让模型更好地适应不同的任务和情况,提高其整体性能和适用性。
方法简介
该研究主要基于一种流行的 AI 智能体方法:ReAct。一个 ReAct 任务解决轨迹由多个「思考 - 行动 - 观察」回合组成。具体来说,让 AI 智能体完成一个任务,语言模型在其中扮演的角色类似于「大脑」。它为 AI 智能体提供解决问题的「思考」和结构化的动作指示,并根据上下文与不同的工具交互,在这个过程中接收观察到的反馈。
在 ReAct 的基础上,作者提出了 FireAct,如图2所示,FireAct 运用强大的语言模型的少样本提示来生成多样化的 ReAct 轨迹,用以微调较小规模的语言模型。与此前类似研究不同的是,FireAct 能够混合多个训练任务和提示方法,大大促进了数据的多样性。
作者还参考了两种与 ReAct 兼容的方法:
思维链(CoT)是生成连接问题和答案的中间推理的有效方法。每个 CoT 轨迹可以简化为一个单轮 ReAct 轨迹,其中「思维」代表中间推理,「行动」代表返回答案。在不需要与应用工具交互的情况下,CoT 尤其有用。
Reflexion 主要遵循 ReAct 轨迹,但加入了额外的反馈和自我反思。该研究中,仅在 ReAct 的第6轮和第10轮提示进行反思。这样一来,长的 ReAct 轨迹就能为解决当前任务提供策略「支点」,能够帮助模型解决或调整策略。例如搜索「电影名」得不到答案时,应该把搜索的关键词换成「导演」。
在推理过程中,FireAct 框架下的 AI 智能体显著减少了提示词的样本数量需求,推理也更加高效和简便。它能够根据任务的复杂度隐式地选择合适的方法。由于 FireAct 具备更广泛和多样化的学习支持,与传统的提示词微调方法相比,它展现出更强的泛化能力和稳健性。
实验及结果
任务数据集:HotpotQA,Bamboogle,StrategyQA,MMLU。
HotpotQA 是一个 QA 数据集,对多步骤推理和知识检索有着更具挑战性的考验。研究者使用2,000个随机训练问题进行微调数据整理,并使用500个随机 dev 问题进行评估。
Bamboogle 是一个由125个多跳问题组成的测试集,其格式与 HotpotQA 相似,但经过精心设计,以避免直接用谷歌搜索解决问题。
StrategyQA 是一个需要隐式推理步骤的是 / 否 QA 数据集。
MMLU 涵盖初等数学、历史和计算机科学等不同领域的57个多选 QA 任务。
工具:研究者使用 SerpAPI1构建了一个谷歌搜索工具,该工具会从「答案框」、「答案片段」、「高亮单词」或「第一个结果片段」中返回第一个存在的条目,从而确保回复简短且相关。他们发现,这样一个简单的工具足以满足不同任务的基本质量保证需求,并提高了微调模型的易用性和通用性。
研究者研究了三个 LM 系列:OpenAI GPT、Llama-2以及 CodeLlama。
微调方法:研究者在大多数微调实验中使用了低秩自适应(Low-Rank Adaptation,LoRA),但在某些比较中也使用了全模型微调。考虑到语言代理微调的各种基本因素,他们将实验分为三个部分,复杂程度依次增加:
在单一任务中使用单一提示方法进行微调;
在单一任务中使用多种方法进行微调;
在多个任务中使用多种方法进行微调。
在单一任务中使用单一提示方法进行微调
研究者探讨了使用来自单一任务(HotpotQA)和单一提示方法(ReAct)的数据进行微调的问题。通过这种简单而可控的设置,他们证实了微调相对于提示的各种优势(性能、效率、稳健性、泛化),并研究了不同 LM、数据大小和微调方法的效果。
如表2所示,微调能持续、显著地改善 HotpotQA EM 的提示效果。虽然较弱的 LM 从微调中获益更多(例如,Llama-2-7B 提高了77%),但即使是像 GPT-3.5这样强大的 LM 也能通过微调将性能提高25%,这清楚地表明了从更多样本中学习的好处。与表1中的强提示基线相比,研究者发现经过微调的 Llama-2-13B 优于所有 GPT-3.5提示方法。这表明对小型开源 LM 进行微调的效果可能优于对更强大的商用 LM 进行提示的效果。
在智能体推理过程中,微调的成本更低,速度更快。由于微调 LM 不需要少量的上下文示例,因此其推理效率更高。例如,表3的第一部分比较了微调推理与 shiyongtishideGPT-3.5推理的成本,发现推理时间减少了70%,总体推理成本也有所降低。
研究者考虑到一个简化且无害的设置,即搜索 API 有0.5的概率返回「None」或随机搜索响应,并询问语言智能体是否仍能稳健地回答问题。如表3第二部分所示,「None」的设置更具挑战性,它使 ReAct EM 降低了33.8%,而 FireAct EM 仅降低了14.2%。这些初步结果表明,更多样化的学习支持对于提高稳健性非常重要。
表3的第三部分显示了经过微调的和使用提示的 GPT-3.5在 Bamboogle 上的 EM 结果。虽然经过 HotpotQA 微调或使用提示的 GPT-3.5都能合理地泛化到 Bamboogle,但前者(44.0EM)仍然优于后者(40.8EM),这表明微调具有泛化优势。
在单一任务中使用多种方法进行微调
作者将 CoT 和 Reflexion 与 ReAct 集成,测试了对于在单一任务(HotpotQA)中使用多种方法进行微调的性能。对比 FireAct 和既有方法的在各数据集中的得分,他们有以下发现:
首先,使用多种方法微调提高了智能体的灵活性。如图5所示,在定量结果之外,研究者向我们展示了两个示例问题,以说明多方法 FireAct 微调的好处。第一个问题比较简单,但仅使用 ReAct 微调的智能体搜索了一个过于复杂的查询,导致注意力分散,提供了错误的答案。相比之下,同时使用 CoT 和 ReAct 微调的智能体自信地选择依靠自己的内部知识,在一轮内完成了任务。第二个问题难度更高,仅使用 ReAct 微调的智能体未搜索出有用的信息。相比之下,同时使用 Reflexion 和 ReAct 微调的智能体在搜索碰壁时进行了反思,并改变了搜索策略,从而得到了正确答案。灵活地为不同问题选择解决方案,是 FireAct 相较于提示等微调方法的关键优势。
其次,使用多方法微调不同的语言模型将产生不同的影响。如表4所示,综合使用多种智能体进行微调并不总是能带来提升,最优的方法组合取决于基础语言模型。例如,对于 GPT-3.5和 Llama-2模型,ReAct CoT 优于 ReAct,但对于 CodeLlama 模型则不同。对于 CodeLlama7/13B,ReAct CoT Reflexion 的效果最差,但 CodeLlama-34B 却能取得最好的效果。这些结果表明,还需进一步研究基础语言模型和微调数据之间的相互作用。
为了进一步了解组合了多种方法的智能体是否能够根据任务选择恰当的解决方案,研究者计算了在推理过程中随机选择方法的得分。该得分(32.4)远低于所有组合了多种方法的智能体,这表明选择解决方案并非易事。然而,每个实例的最佳方案的得分也仅为52.0,这表明在提示方法选择方面仍有提升空间。
在多个任务中使用多种方法进行微调
到这里,微调只使用了 HotpotQA 数据,但有关 LM 微调的实证研究表明,混合使用不同的任务会有益处。研究者使用来自三个数据集的混合训练数据对 GPT-3.5进行微调:HotpotQA(500个 ReAct 样本,277个 CoT 样本)、StrategyQA(388个 ReAct 样本,380个 CoT 样本)和 MMLU(456个 ReAct 样本,469个 CoT 样本)。
如表5所示,加入 StrategyQA/MMLU 数据后,HotpotQA/Bamboogle 的性能几乎保持不变。一方面,StrategyQA/MMLU 轨迹包含的问题和工具使用策略大不相同,这使得迁移变得困难。另一方面,尽管分布发生了变化,但加入 StrategyQA/MMLU 并没有影响 HotpotQA/Bamboogle 的性能,这表明微调一个多任务代理以取代多个单任务代理是未来可以发展的方向。当研究者从多任务、单一方法微调切换到多任务、多方法微调时,他们发现所有任务的性能都有所提高,这再次明确了多方法代理微调的价值。
想要了解更多技术细节,请阅读原文。
剧情低俗!微信:下架微短剧《大佬 你女儿被婆婆家欺负惨了》
快科技6月4日消息,微信珊瑚安全官方公众号今天发布公告称,平台近期已发布专项治理公告,持续打击传播不良价值观等违规微短剧内容。在专项治理期间发现微短剧《大佬,你女儿被婆婆家欺负惨了》存在剧情低俗,台词、画面、情节等涉及使用残忍犯罪手段造成恶劣后果,刻意制造放大和渲染婆媳、男女矛盾。此外还传播违反公序良俗言论,渲染血腥暴力,破坏了平台良好生态,平台已将该剧下架,现予以公示。站长网2024-06-05 12:31:160000去不起直播间的国货们,在泼天流量里“捡粉丝”
最高端的商战,往往以最质朴的形式出现。李佳琦不恰当言论事件之后,关于79元买眉笔到底贵不贵这件事的议论范围越来越大,消费者们开始重新探索究竟用79元能买到哪些东西。风波当中,蜂花、莲花、鸿星尔克纷纷推出79元的产品套组,一度卖到断货。在强烈的对比之下,0.07g的眉笔与真正便宜又大碗的老牌国货之间,消费者已经做出了自己的选择。站长网2023-09-15 18:29:450003科学家公布最新全球红树林分布数据集
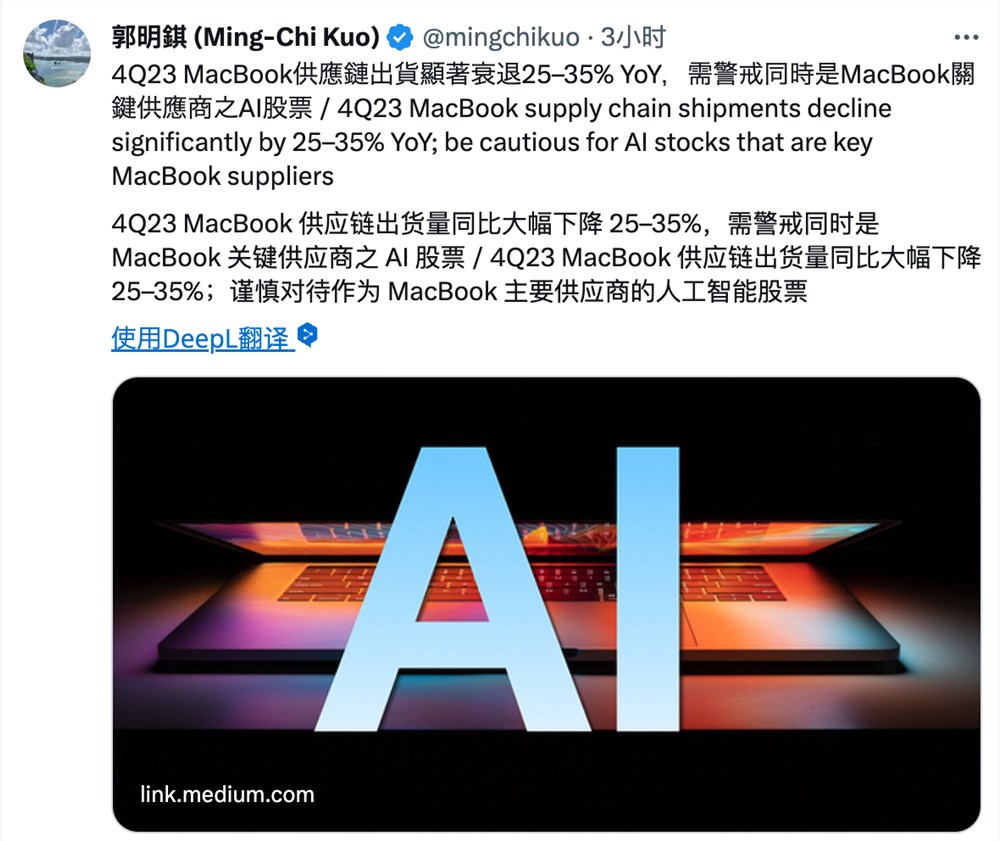
海南儋州新英红树林。(资料图)贾明明供图海南海桑红树林。(资料图)贾明明供图记者近日从中国科学院东北地理与农业生态研究所获悉,中美两国科学家最新联合研究表明,全球红树林生境较为破碎,截至2020年,全球红树林斑块约有33.7万个,其中95%以上斑块的面积小于1平方千米。站长网2023-05-25 06:12:130000郭明錤:谨慎对待作为 MacBook 主要供应商的人工智能股票
站长之家(ChinaZ.com)10月18日消息:知名分析师郭明錤指出,基于供应链的出货情况,预估四季度苹果MacBook出货量将同比下降25-35%;预计2023年全年MacBook出货将同比下降约30%至约1700万部。站长网2023-10-18 22:13:480000Hugging Face、GitHub 等联合呼吁欧盟在AI法规中保护开源创新
HuggingFace、GitHub、EleutherAI、CreativeCommons、LAION和OpenFuture等开源AI利益相关者组成的联盟呼吁欧盟政策制定者在制定《欧盟AI法案》时保护开源创新。站长网2023-07-26 16:37:420000