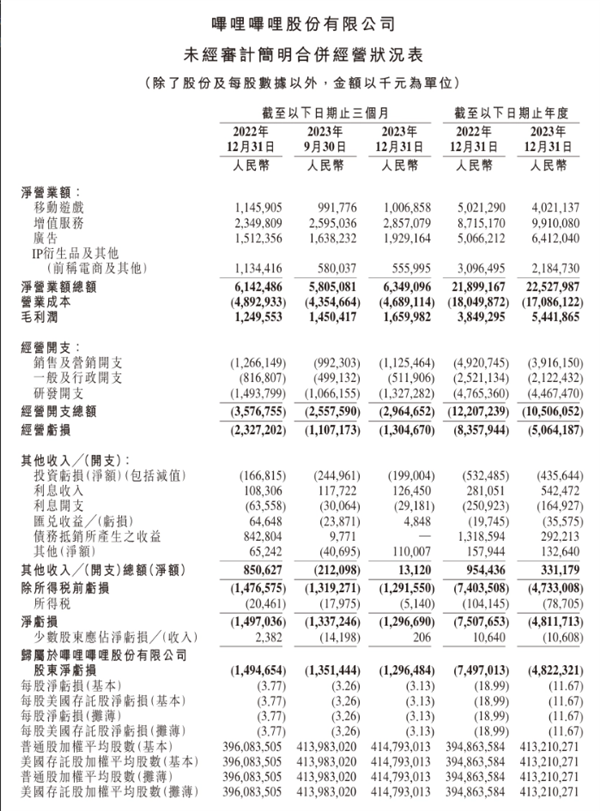
专用于手机、笔记本,Stability.ai开源ChatGPT基因的大模型
12月8日,著名开源生成式AI平台stability.ai在官网开源了,30亿参数的大语言模型StableLM Zephyr3B。
Zephyr3B专用于手机、笔记本等移动设备,主打参数小、性能强、算力消耗低的特点,可自动生成文本、总结摘要等,可与70亿、130亿参数的模型相媲美。
值得一提的是,该模型的核心架构来自Zephyr7B,并进行了精调。而Zephyr7B是基于前几天刚获35亿元巨额融资Mistral AI的Mistral-7B模型微调而成。
同时使用了GPT-3.5生成了训练数据集以及GPT-4对其进行了人工智能反馈,所以,Zephyr3B是有多家大厂模型基因的超级缝合怪。
Zephyr3B开源地址:https://huggingface.co/stabilityai/stablelm-zephyr-3b
Zephyr7B开源地址:https://huggingface.co/HuggingFaceH4/zephyr-7b-beta
由于Stability.ai并没有开放Zephyr3B的论文,只能从Zephyr7B的技术文档为大家解读一下其核心架构,主要包含监督学习优化、人工智能反馈和直觉优化指导学习三大模块。
由于该模型在训练数据集和人工智能反馈等方面使用了GPT系列模型,有很强的ChatGPT基因。
监督学习优化(dSFT)
研究人员通过OpenAI的GPT-3.5模型生成了规模庞大的对话数据集“UltraChat”,超过147万条多轮不同主题对话示例。
然后通过该数据集对模型进行监督学习优化,训练样本是对话内容和回复,以最大程度降低“交叉熵”误差。
该流程类似传统的监督学习方法,将模型训练任务指定到给定数据集上。
但与使用人工数据集略有不同,该方法直接使用了强大语言模型自主生成高质量的训练数据,避免了人工乱标注难题。
人工智能反馈(AIF)
为了进一步提升模型的文本生成、理解的精准度,研究人员使用了第二个数据集UltraFeedback,对4个不同的大语言模型,在不同主题下的回复进行打分评价。
具体方法是将每条对话的文本提示送入到4个模型,得到4个答案,然后再由“教师模型”GPT-4进行打分(0—10分)。最高分答案为“优先答案”,随机选择另一个作为“非优先答案”进行深度优化。
直觉优化指导学习(dDPO)
通过使用前面的“UltraFeedback”收集的GPT-4对话样本及质量评价,提取高分和低分样本作为数据配对组。
就是按批处理对优先和非优先样本计算两种概率,并利用损失函数测量它们的差异,通过反向传播优化模型参数。
该算法以试批方式运行,在每轮中随机选取样本对,计算当前模型与基线模型在这两个样本上的概率误差。
通过这种反向传播将误差回溯至参数,可实时地微调模型结构。整个优化流程非常高效,无需采样,几小时就能完成,并且不需任何人工标注。
测试数据
Stability.ai表示,Zephyr3B在MT Bench、AlpacaEval等平台进行了测试,在生成上下文相关、连贯和语言准确等文本方面的表现非常优秀。
特别擅长创意、个性化文本生成,同时能根据用户输入的数据进行分析。
其性能可与Falcon-4b-Instruct、WizardLM-13B-v1、Llama-2-70b-chat 和 Claude-V1等几个大参数模型相媲美。
腾讯:混元AI大模型构建进展顺利 正在取得良好进展
在昨日的电话会议上,针对旗下AI大模型混元相关问题,腾讯方面表示,AI基础模型混元正在取得良好进展,模型构建进展顺利。模型训练方面,目前我们正在积极对训练部门及生产线扩容。基础设施建设方面,考虑到腾讯的云业务,AI模型将在未来成为我们的核心优势。腾讯的关键优势之一在于人工智能在产品中的应用。站长网2023-05-18 09:51:380000美团直播:排头兵先行,主力军未动
折扣给得扎实,用户薅得开心,商家进度“参差不齐”。“1.5元买到了甜啦啦的冰鲜柠檬水”“6元拿下原价16元一杯的Tims鲜萃咖啡,咖啡爱好者的快活”“抢到了6份一块钱的古茗,还有1份1块钱的瑞幸美式咖啡”在刚过去的7月18日美团“神券节官方直播间”开播当日,不乏有美团用户在小红书上兴奋得分享着“战利品”。继八年前的“外卖大战”后,“个位数点外卖”的“羊毛”又重出江湖了。站长网2023-07-21 22:05:350000ChatGPT 的创造性思维可以与排名前 1% 的人类相媲美
蒙大拿大学的一项新研究表明,人工智能聊天机器人ChatGPT可以与人类中排名前1%的最顶尖的思考者相媲美。研究人员将经常使用的创造性思维测试Torrance(TTCT,一种常用的创造力测试)应用于ChatGPT,并记录了八个回答。他们还收集了蒙大拿大学24名学生的回答。这些分数与全美2700名参加TTCT测试的学生进行了比较。站长网2023-07-18 16:35:000000ChatExcel AI 办公辅助工具:通过文字聊天操控 Excel 表格
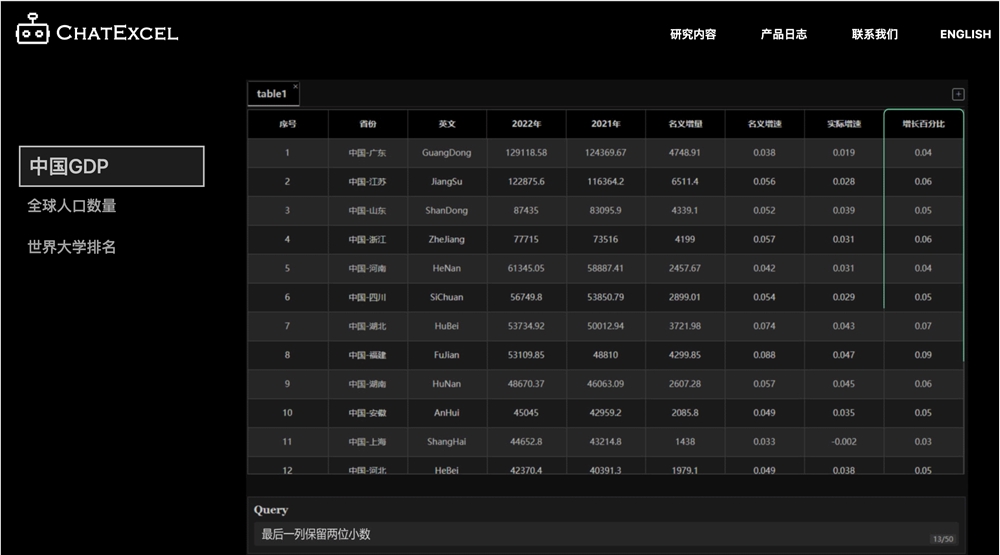
站长之家(ChinaZ.com)4月19日消息:最近,一支团队在北京大学深圳研究生院信息工程学院研发出了一款名为ChatExcel的AI办公辅助工具。站长网2023-04-19 10:10:450000爆火全网的AI硬件AI Pin遭炮轰 不就是谷歌眼镜+寻呼机?
要点:AIPin作为一款可穿戴AI硬件,在其发布后受到了巨大的质疑,主要集中在不支持第三方APP、缺乏实体屏幕、本地计算性能较低、安全隐私隐患等方面。批评者认为AIPin的操作限制,例如不支持第三方APP和没有实体屏幕,使得用户交互变得复杂,而且其本地处理能力较差,对云上计算依赖较大。同时,安全隐私问题也成为关注焦点。站长网2023-11-14 11:58:180000